етЦЊНЬГЬЧГЮіPythonЪЕЯжDFAЫуЗЈаДЕУКмЪЕгУЃЌЯЃЭћФмАяЕНФњЁЃ
вЛЁЂИХЪіМЦЫуЛњВйзїЯЕЭГжаЕФНјГЬзДЬЌгыЧаЛЛПЩвдзїЮЊ DFA ЫуЗЈЕФвЛжжНќЫЦРэНтЁЃШчЯТЭМЫљЪОЃЌЦфжаЭждВБэЪОзДЬЌЃЌзДЬЌжЎМфЕФСЌЯпБэЪОЪТМўЃЌНјГЬЕФзДЬЌвдМАЪТМўЖМЪЧПЩШЗЖЈЕФЃЌЧвЖМПЩвдЧюОйЁЃ 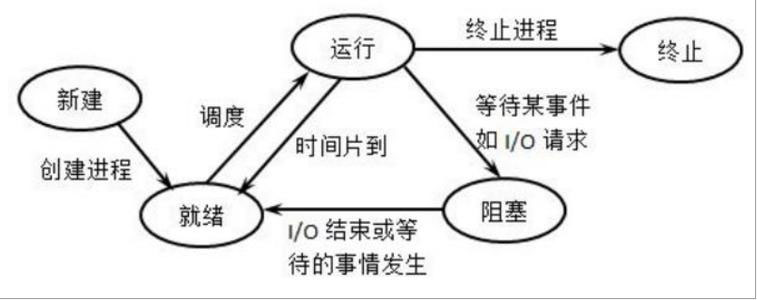
DFA ЫуЗЈОпгаЖржжгІгУЃЌдкДЫЯШНщЩмдкЦЅХфЙиМќДЪСьгђЕФгІгУЁЃ
ЖўЁЂЦЅХфЙиМќДЪЮвУЧПЩвдНЋУПИіЮФБОЦЌЖЮзїЮЊзДЬЌЃЌР§ШчЁАЦЅХфЙиМќДЪЁБПЩВ№ЗжЮЊЁАЦЅЁБЁЂЁАЦЅХфЁБЁЂЁАЦЅХфЙиЁБЁЂЁАЦЅХфЙиМќЁБКЭЁАЦЅХфЙиМќДЪЁБЮхИіЮФБОЦЌЖЮЁЃ 
ЁОЙ§ГЬЁПЃК - ГѕЪМзДЬЌЮЊПеЃЌЕБДЅЗЂЪТМўЁАЦЅЁБЪБзЊЛЛЕНзДЬЌЁАЦЅЁБЃЛ
- ДЅЗЂЪТМўЁАХфЁБЃЌзЊЛЛЕНзДЬЌЁАЦЅХфЁБЃЛ
- вРДЮРрЭЦЃЌжБЕНзЊЛЛЮЊзюКѓвЛИізДЬЌЁАЦЅХфЙиМќДЪЁБЁЃ
дйШУЮвУЧПМТЧЖрИіЙиМќДЪЕФЧщПіЃЌР§ШчЁАЦЅХфЫуЗЈЁБЁЂЁАЦЅХфЙиМќДЪЁБвдМАЁАаХЯЂГщШЁЁБЁЃ 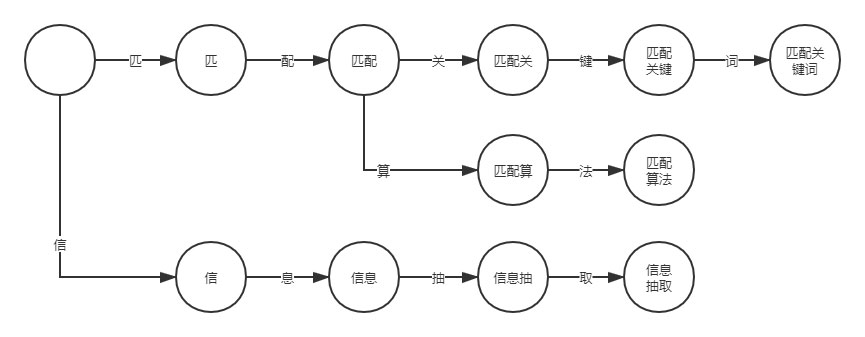
ПЩвдПДЕНЩЯЭМЕФзДЬЌЭМРрЫЦЪїаЮНсЙЙЃЌвВе§ЪЧвђЮЊетИіНсЙЙЃЌЪЙЕУ DFA ЫуЗЈдкЙиМќДЪЦЅХфЗНУцвЊПьгкЙиМќДЪЕќДњЗНЗЈЃЈfor бЛЗЃЉЁЃОГЃЫЂ LeetCode ЕФЖСепгІИУЧхГўЪїаЮНсЙЙЕФЪБМфИДдгЖШвЊаЁгк for бЛЗЕФЪБМфИДдгЖШЁЃ for бЛЗЃК keyword_list = []for keyword in ["ЦЅХфЫуЗЈ", "ЦЅХфЙиМќДЪ", "аХЯЂГщШЁ"]: if keyword in "DFA ЫуЗЈЦЅХфЙиМќДЪ": keyword_list.append(keyword) for бЛЗашвЊБщРњвЛБщЙиМќДЪБэЃЌЫцзХЙиМќДЪБэЕФРЉГфЃЌЫљашЕФЪБМфвВЛсдНРДдНГЄЁЃ DFA ЫуЗЈЃКевЕНЁАЦЅЁБЪБЃЌжЛЛсАДееЪТМўзпЯђЬиЖЈЕФађСаЃЌР§ШчЁАЦЅХфЙиМќДЪЁБЃЌЖјВЛЛсзпЯђЁАЦЅХфЫуЗЈЁБЃЌвђДЫБщРњЕФДЮЪ§вЊаЁгк for бЛЗЁЃОпЬхЕФЪЕЯжЗХдкЯТЮФжаЁЃ ЁОЮЪЁПЃКФЧУДШчКЮЙЙНЈзДЬЌЭМЫљЪОЕФНсЙЙФиЃП ЁОД№ЁПЃКдк Python жаЮвУЧПЩвдЪЙгУ dict Ъ§ОнНсЙЙЁЃ state_event_dict = { "ЦЅ": { "Хф": { "Ыу": { "ЗЈ": { "is_end": True }, "is_end": False }, "Йи": { "Мќ": { "ДЪ": { "is_end": True }, "is_end": False }, "is_end": False }, "is_end": False }, "is_end": False }, "аХ": { "ЯЂ": { "Гщ": { "ШЁ": { "is_end": True }, "is_end": False }, "is_end": False }, "is_end": False }}гУЧЖЬззжЕфРДзїЮЊЪїаЮНсЙЙЃЌkey зїЮЊЪТМўЃЌЭЈЙ§ is_end зжЖЮРДХаЖЯзДЬЌЪЧЗёЮЊзюКѓвЛИізДЬЌЃЌШчЙћЪЧзюКѓвЛИізДЬЌЃЌдђЭЃжЙзДЬЌзЊЛЛЃЌЛёШЁЦЅХфЕФЙиМќДЪЁЃ ЁОЮЪЁПЃКШчЙћЙиМќДЪДцдкАќКЌЙиЯЕЃЌР§ШчЁАЦЅХфЙиМќДЪЁБКЭЁАЦЅХфЁБЃЌФЧУДИУШчКЮДІРэФиЃП ЁОД№ЁПЃКЮвУЧШдШЛПЩвдгУ is_end зжЖЮРДБэЪОЙиМќДЪЕФНсЮВЃЌЭЌЪБЬэМгвЛИіаТЕФзжЖЮЃЌР§Шч is_continue РДБэУїШдПЩМЬајНјааЦЅХфЁЃГ§ДЫжЎЭтЃЌвВПЩвдЭЈЙ§бАевГ§ is_end зжЖЮЭтЪЧЗёЛЙгаЦфЫћЕФзжЖЮРДХаЖЯЪЧЗёМЬајНјааЦЅХфЁЃР§ШчЯТУцДњТыжаЕФЁАХфЁБЃЌГ§СЫ is_end зжЖЮЭтЛЙгаЁАЙиЁБЃЌвђДЫЛЙашвЊМЬајНјааЦЅХфЁЃ state_event_dict = { "ЦЅ": { "Хф": { "Йи": { "Мќ": { "ДЪ": { "is_end": True }, "is_end": False }, "is_end": False }, "is_end": True }, "is_end": False }}НгЯТРДЃЌЮвУЧРДЪЕЯжетИіЫуЗЈЁЃ
Ш§ЁЂЫуЗЈЪЕЯжЪЙгУ Python 3.6 АцБОЪЕЯжЃЌЕБШЛ Python 3.X ЖМФмдЫааЁЃ
3.1ЁЂЙЙНЈДцДЂНсЙЙdef _generate_state_event_dict(keyword_list: list) -> dict: state_event_dict = {} # БщРњУПвЛИіЙиМќДЪ for keyword in keyword_list: current_dict = state_event_dict length = len(keyword) for index, char in enumerate(keyword): if char not in current_dict: next_dict = {"is_end": False} current_dict[char] = next_dict current_dict = next_dict else: next_dict = current_dict[char] current_dict = next_dict if index == length - 1: current_dict["is_end"] = True return state_event_dictЙигкЩЯЪіДњТыШдШЛгаВЛЩйПЩЕќДњгХЛЏЕФЕиЗНЃЌР§ШчЯШЖдЙиМќДЪСаБэАДеезжЕфађНјааХХађЃЌетбљПЩвдШУОпгаЯрЭЌЧАзКЕФЙиМќДЪМЏжадквЛПщЃЌДгЖјдкЙЙНЈДцДЂНсЙЙЪБФмЙЛМѕЩйБщРњЕФДЮЪ§ЁЃ
3.2ЁЂЦЅХфЙиМќДЪdef match(state_event_dict: dict, content: str): match_list = [] state_list = [] temp_match_list = [] for char_pos, char in enumerate(content): # ЪзЯШевЕНЦЅХфЯюЕФЦ№Еу if char in state_event_dict: state_list.append(state_event_dict) temp_match_list.append({ "start": char_pos, "match": "" }) # ПЩФмЛсЭЌЪБТњзуЖрИіЦЅХфЯюЃЌвђДЫБщРњетаЉЦЅХфЯю for index, state in enumerate(state_list): if char in state: state_list[index] = state[char] temp_match_list[index]["match"] += char # ШчЙћЕжДяЦЅХфЯюЕФНсЮВЃЌБэУїЦЅХфЙиМќДЪЭъГЩ if state[char]["is_end"]: match_list.append(copy.deepcopy(temp_match_list[index])) # ШчЙћЛЙФмМЬајЃЌдђМЬајНјааЦЅХф if len(state[char].keys()) == 1: state_list.pop(index) temp_match_list.pop(index) # ШчЙћВЛТњзуЦЅХфЯюЕФвЊЧѓЃЌдђНЋЦфвЦГ§ else: state_list.pop(index) temp_match_list.pop(index) return match_list
3.3ЁЂЭъећДњТыimport reimport copyclass DFA: def __init__(self, keyword_list: list): self.state_event_dict = self._generate_state_event_dict(keyword_list) def match(self, content: str): match_list = [] state_list = [] temp_match_list = [] for char_pos, char in enumerate(content): if char in self.state_event_dict: state_list.append(self.state_event_dict) temp_match_list.append({ "start": char_pos, "match": "" }) for index, state in enumerate(state_list): if char in state: state_list[index] = state[char] temp_match_list[index]["match"] += char if state[char]["is_end"]: match_list.append(copy.deepcopy(temp_match_list[index])) if len(state[char].keys()) == 1: state_list.pop(index) temp_match_list.pop(index) else: state_list.pop(index) temp_match_list.pop(index) return match_list @staticmethod def _generate_state_event_dict(keyword_list: list) -> dict: state_event_dict = {} for keyword in keyword_list: current_dict = state_event_dict length = len(keyword) for index, char in enumerate(keyword): if char not in current_dict: next_dict = {"is_end": False} current_dict[char] = next_dict current_dict = next_dict else: next_dict = current_dict[char] current_dict = next_dict if index == length - 1: current_dict["is_end"] = True return state_event_dictif __name__ == "__main__": dfa = DFA(["ЦЅХфЙиМќДЪ", "ЦЅХфЫуЗЈ", "аХЯЂГщШЁ", "ЦЅХф"]) print(dfa.match("аХЯЂГщШЁжЎ DFA ЫуЗЈЦЅХфЙиМќДЪЃЌЦЅХфЫуЗЈ"))ЪфГіЃК [ { 'start': 0, 'match': 'аХЯЂГщШЁ' }, { 'start': 12, 'match': 'ЦЅХф' }, { 'start': 12, 'match': 'ЦЅХфЙиМќДЪ' }, { 'start': 18, 'match': 'ЦЅХф' }, { 'start': 18, 'match': 'ЦЅХфЫуЗЈ' } ]
ЫФЁЂЦфЫћгУЗЈ
4.1ЁЂЬэМгЭЈХфЗћдкУєИаДЪЪЖБ№ЪБЭљЭљЛсгіЕНЭЌвЛжжРраЭЕФОфЪНЃЌР§ШчЁАФуетИіЩЕXЁБЃЌЦфжа X ПЩвдгаКмЖрЃЌФбЕРЮвУЧашвЊвЛИіИіЬэМгЕНЙиМќДЪБэжаТ№ЃПзюКУФмЙЛЭЈЙ§РрЫЦе§дђБэДяЪНЕФЗНЗЈШЅНјааЪЖБ№ЁЃвЛИіМђЕЅЕФзіЗЈОЭЪЧЁА*ЁБЃЌЦЅХфШЮКЮФкШнЁЃ ЬэМгЭЈХфЗћжЛашвЊЖдЦЅХфЙиМќДЪЙ§ГЬНјаааоИФЃК def match(self, content: str): match_list = [] state_list = [] temp_match_list = [] for char_pos, char in enumerate(content): if char in self.state_event_dict: state_list.append(self.state_event_dict) temp_match_list.append({ "start": char_pos, "match": "" }) for index, state in enumerate(state_list): is_find = False state_char = None # ШчЙћЪЧ * дђЦЅХфЫљгаФкШн if "*" in state: state_list[index] = state["*"] state_char = state["*"] is_find = True if char in state: state_list[index] = state[char] state_char = state[char] is_find = True if is_find: temp_match_list[index]["match"] += char if state_char["is_end"]: match_list.append(copy.deepcopy(temp_match_list[index])) if len(state_char.keys()) == 1: state_list.pop(index) temp_match_list.pop(index) else: state_list.pop(index) temp_match_list.pop(index) return match_listmain() КЏЪ§ЁЃ if __name__ == "__main__": dfa = DFA(["ЦЅХфЙиМќДЪ", "ЦЅХфЫуЗЈ", "аХЯЂ*ШЁ", "ЦЅХф"]) print(dfa.match("аХЯЂГщШЁжЎ DFA ЫуЗЈЦЅХфЙиМќДЪЃЌЦЅХфЫуЗЈЃЌаХЯЂзЅШЁ"))ЪфГіЃК [ { 'start': 0, 'match': 'аХЯЂГщШЁ' }, { 'start': 12, 'match': 'ЦЅХф' }, { 'start': 12, 'match': 'ЦЅХфЙиМќДЪ' }, { 'start': 18, 'match': 'ЦЅХф' }, { 'start': 18, 'match': 'ЦЅХфЫуЗЈ' }, { 'start': 23, 'match': 'аХЯЂзЅШЁ' } ]
вдЩЯОЭЪЧЧГЮіPythonЪЕЯжDFAЫуЗЈЕФЯъЯИФкШнЃЌИќЖрЙигкPython DFAЫуЗЈЕФзЪСЯЧыЙизЂ51zixue.netЦфЫќЯрЙиЮФеТЃЁ
НтЮіФПБъМьВтжЎIoU
ЧГЮіDjangoНгПкАцБОПижЦ |


