这篇教程python中pandas对多列进行分组统计的实现写得很实用,希望能帮到您。
使用groupby([ ]).size()统计的结果,值相同的字段值会不显示
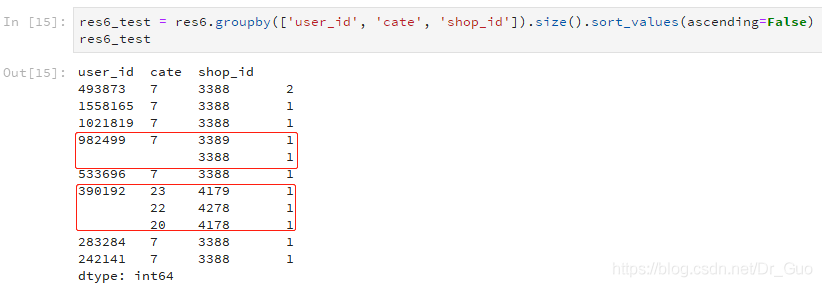
如上图所示,第一个空着的行是982499 7 3388 1,因为此行与前面一行的这两个字段值是一样的,所以不显示。第二个空着的行是390192 22 4278 1,因为此行与前面一行的第一个字段值是一样的,所以不显示。这样的展示方式更直观,但对于刚用的人,可能会让其以为是缺失值。
如果还不明白可以看下面的全部数据及操作。 import pandas as pdres6 = pd.read_csv('test.csv')res6.shapeIndex(['user_id', 'cate', 'shop_id'], dtype='object') <class 'pandas.core.frame.DataFrame'>RangeIndex: 12 entries, 0 to 11Data columns (total 3 columns):user_id 12 non-null int64cate 12 non-null int64shop_id 12 non-null int64dtypes: int64(3)memory usage: 368.0 bytes | user_id | cate | shop_id | | count | 1.200000e+01 | 12.000000 | 12.000000 | | mean | 6.468688e+05 | 10.666667 | 3594.000000 | | std | 3.988181e+05 | 6.665151 | 373.271775 | | min | 2.421410e+05 | 7.000000 | 3388.000000 | | 25% | 3.901920e+05 | 7.000000 | 3388.000000 | | 50% | 4.938730e+05 | 7.000000 | 3388.000000 | | 75% | 9.824990e+05 | 10.250000 | 3586.250000 | | max | 1.558165e+06 | 23.000000 | 4278.000000 | | user_id | cate | shop_id | | 0 | 390192 | 20 | 4178 | | 1 | 390192 | 23 | 4179 | | 2 | 390192 | 22 | 4278 | | 3 | 1021819 | 7 | 3388 | | 4 | 242141 | 7 | 3388 | | 5 | 283284 | 7 | 3388 | | 6 | 1558165 | 7 | 3388 | | 7 | 533696 | 7 | 3388 | | 8 | 982499 | 7 | 3388 | | 9 | 493873 | 7 | 3388 | | 10 | 493873 | 7 | 3388 | | 11 | 982499 | 7 | 3389 | res6['user_id'].value_counts() 390192 3982499 2493873 2242141 11021819 1533696 11558165 1283284 1Name: user_id, dtype: int64 res6.groupby(['user_id']).size().sort_values(ascending=False) user_id390192 3982499 2493873 21558165 11021819 1533696 1283284 1242141 1dtype: int64 res6.groupby(['user_id', 'cate']).size().sort_values(ascending=False) user_id cate982499 7 2493873 7 21558165 7 11021819 7 1533696 7 1390192 23 1 22 1 20 1283284 7 1242141 7 1dtype: int64 res6_test = res6.groupby(['user_id', 'cate', 'shop_id']).size().sort_values(ascending=False)res6_test user_id cate shop_id493873 7 3388 21558165 7 3388 11021819 7 3388 1982499 7 3389 1 3388 1533696 7 3388 1390192 23 4179 1 22 4278 1 20 4178 1283284 7 3388 1242141 7 3388 1dtype: int64 到此这篇关于python中pandas对多列进行分组统计的实现的文章就介绍到这了,更多相关pandas多列分组统计内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
python 常用的异步框架汇总整理
用Python selenium实现淘宝抢单机器人 |
