етЦЊНЬГЬPython scrapyХРШЁЫежнЖўЪжЗПНЛвзЪ§ОнаДЕУКмЪЕгУЃЌЯЃЭћФмАяЕНФњЁЃ
вЛЁЂЯюФПашЧѓЪЙгУScrapyХРШЁСДМвЭјжаЫежнЪаЖўЪжЗПНЛвзЪ§ОнВЂБЃДцгкCSVЮФМўжа
вЊЧѓЃК
ЗПЮнУцЛ§ЁЂзмМлКЭЕЅМлжЛашвЊОпЬхЕФЪ§зжЃЌВЛашвЊЕЅЮЛУћГЦЁЃ
ЩОГ§зжЖЮВЛШЋЕФЗПЮнЪ§ОнЃЌШчгаЕФЗПЮнГЏЯђЛсЯдЪОЁАднЮоЪ§ОнЁБЃЌгІИУЬоГ§ЁЃ
БЃДцЕНCSVЮФМўжаЕФЪ§ОнЃЌзжЖЮвЊАДееШчЯТЫГађХХСаЃКЗПЮнУћГЦЃЌЗПЮнЛЇаЭЃЌНЈжўУцЛ§ЃЌЗПЮнГЏЯђЃЌзАаоЧщПіЃЌгаЮоЕчЬнЃЌЗПЮнзмМлЃЌЗПЮнЕЅМлЃЌЗПЮнВњШЈЁЃ ЖўЁЂЯюФПЗжЮіСїГЬЭМ 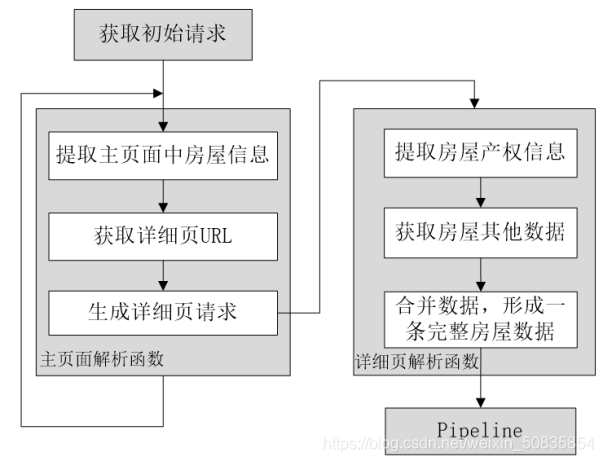
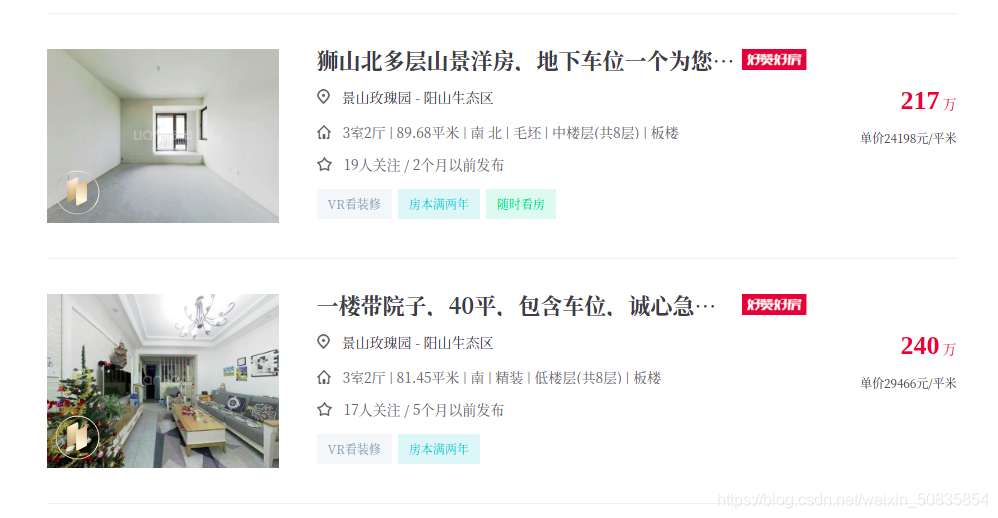

ЭЈЙ§ПижЦЬЈЗЂЯжЫљгаЗПЮнаХЯЂЖМдквЛИіulжаЦфжаУПвЛИіliРяДцДЂвЛИіЗПЮнЕФаХЯЂЁЃ 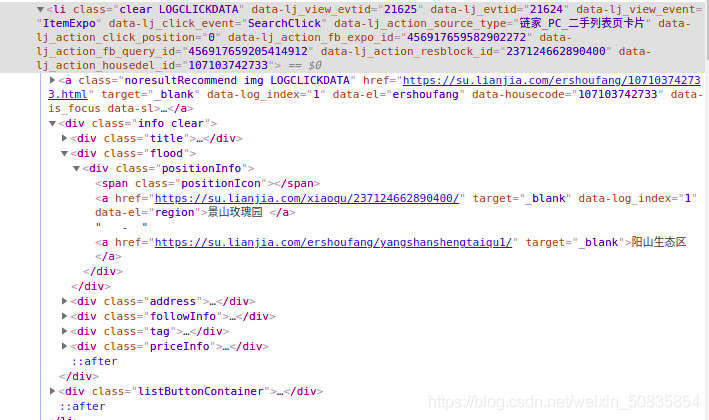
евСЫЕНашвЊЕФзжЖЮЃЌетРявдЗПЮнУћГЦЮЊР§ЃЌВЉжїгУlinuxНиЭМЃЌУЛЗЈЖдЭМЦЌНјааБъзЂЃЌетвЛЖЮОЭЪЧзюжаМфЕФЁАОАЩНУЕЙхдАЁБ ЁЃ
ЦфЫћзжЖЮРрЫЦВЛдйвЛвЛСаОйЁЃ
ЛёШЁСЫашвЊЕФЪ§ОнКѓЗЂЯжУЛгаЕчЬнЕФХфБИЧщПіЃЌЫљвдашвЊЕНЯъЯИвГвВОЭЪЧЕуЛїБъЬтКѓНјШыЕФвГУцЃЌ
ЕуЛїБъЬт 
ПЩвдПДЕНРяУцгаЯТашвЊЕФаХЯЂЁЃ 
зЅШЁЯъЯИвГurl 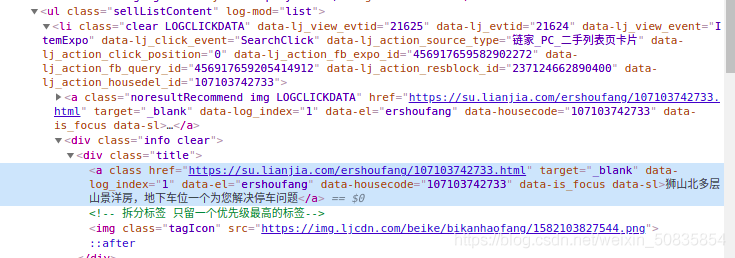
НјааЯъЯИвГЪ§ОнЗжЮі 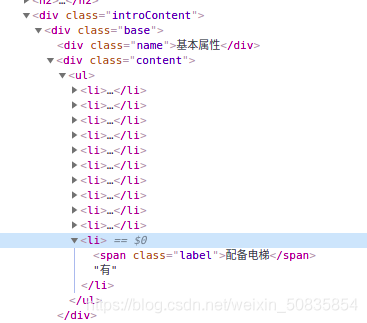
евЕНЯргІЕФЮЛжУЃЌНјаазЅШЁЪ§ОнЁЃ Ш§ЁЂБраДГЬађДДНЈЯюФПЃЌВЛЫЕСЫЁЃ 1.БраДitemЃЈЪ§ОнДцДЂЃЉ import scrapyclass LianjiaHomeItem(scrapy.Item): name = scrapy.Field() # УћГЦ type = scrapy.Field() # ЛЇаЭ area = scrapy.Field() # УцЛ§ direction = scrapy.Field() #ГЏЯђ fitment = scrapy.Field() # зАаоЧщПі elevator = scrapy.Field() # гаЮоЕчЬн total_price = scrapy.Field() # змМл unit_price = scrapy.Field() # ЕЅМл 2.БраДspiderЃЈЪ§ОнзЅШЁЃЉ from scrapy import Requestfrom scrapy.spiders import Spiderfrom lianjia_home.items import LianjiaHomeItemclass HomeSpider(Spider): name = "home" current_page=1 #Ц№ЪМвГ def start_requests(self): #ГѕЪМЧыЧѓ url="https://su.lianjia.com/ershoufang/" yield Request(url=url) def parse(self, response): #НтЮіКЏЪ§ list_selctor=response.xpath("//li/div[@class='info clear']") for one_selector in list_selctor: try: #ЗПЮнУћГЦ name=one_selector.xpath("//div[@class='flood']/div[@class='positionInfo']/a/text()").extract_first() #ЦфЫћаХЯЂ other=one_selector.xpath("//div[@class='address']/div[@class='houseInfo']/text()").extract_first() other_list=other.split("|") type=other_list[0].strip(" ")#ЛЇаЭ area = other_list[1].strip(" ") #УцЛ§ direction=other_list[2].strip(" ") #ГЏЯђ fitment=other_list[3].strip(" ") #зАао price_list=one_selector.xpath("div[@class='priceInfo']//span/text()") # змМл total_price=price_list[0].extract() # ЕЅМл unit_price=price_list[1].extract() item=LianjiaHomeItem() item["name"]=name.strip(" ") item["type"]=type item["area"] = area item["direction"] = direction item["fitment"] = fitment item["total_price"] = total_price item["unit_price"] = unit_price #ЩњГЩЯъЯИвГ url = one_selector.xpath("div[@class='title']/a/@href").extract_first() yield Request(url=url, meta={"item":item}, #АбitemзїЮЊЪ§ОнvДЋЕн callback=self.property_parse) #ХРШЁЯъЯИвГ except: print("error") #ЛёШЁЯТвЛвГ self.current_page+=1 if self.current_page<=100: next_url="https://su.lianjia.com/ershoufang/pg%d"%self.current_page yield Request(url=next_url) def property_parse(self,response):#ЯъЯИвГ #ХфБИЕчЬн elevator=response.xpath("//div[@class='base']/div[@class='content']/ul/li[last()]/text()").extract_first() item=response.meta["item"] item["elevator"]=elevator yield item3.БраДpipelinesЃЈЪ§ОнДІРэЃЉ import refrom scrapy.exceptions import DropItemclass LianjiaHomePipeline:#Ъ§ОнЕФЧхЯД def process_item(self, item, spider): #УцЛ§ item["area"]=re.findall("/d+/.?/d*",item["area"])[0] #ЬсШЁЪ§зжВЂДцДЂ #ЕЅМл item["unit_price"] = re.findall("/d+/.?/d*", item["unit_price"])[0] #ЬсШЁЪ§зжВЂДцДЂ #ШчЙћгаВЛЭъШЋЕФЪ§ОнЃЌдђХзЦњ if item["direction"] =="днЮоЪ§Он": raise DropItem("ЮоЪ§ОнЃЌХзЦњЃК%s"%item) return itemclass CSVPipeline(object): file=None index=0 #csvЮФМўааЪ§ХаЖЯ def open_spider(self,spider): #ХРГцПЊЪМЧАЃЌДђПЊcsvЮФМў self.file=open("home.csv","a",encoding="utf=8") def process_item(self, item, spider):#АДвЊЧѓДцДЂЮФМўЁЃ if self.index ==0: column_name="name,type,area,direction,fitment,elevator,total_price,unit_price/n" self.file.write(column_name)#ВхШыЕквЛааЕФЫїв§аХЯЂ self.index=1 home_str=item["name"]+","+item["type"]+","+item["area"]+","+item["direction"]+","+item["fitment"]+","+item["elevator"]+","+item["total_price"]+","+item["unit_price"]+"/n" self.file.write(home_str) #ВхШыЛёШЁЕФаХЯЂ return item def close_soider(self,spider):#ХРГцНсЪјКѓЙиБеcsv self.file.close()4.БраДsettingsЃЈХРГцЩшжУЃЉ етРяжЛаДЯТашвЊаоИФЕФЕиЗН USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'#ЮЊзАГЩфЏРРЦїROBOTSTXT_OBEY = False #ВЛзёбrobotsавщITEM_PIPELINES = { 'lianjia_home.pipelines.LianjiaHomePipeline': 300, #ЯШНјааЪ§зжЬсШЁ 'lianjia_home.pipelines.CSVPipeline': 400 #дкНјааЪ§ОнЕФДЂДц #жДааЫГађгЩКѓБпЕФЪ§зжОіЖЈ}етаЉФкШндкsettingsгааЉЪЧФЌШЯЙиБеЕФЃЌАбгУРДзЂЪЭЕФ # ШЅЕєМДПЩПЊЦєЁЃ 5.БраДstartЃЈДњЬцУќСюааЃЉ from scrapy import cmdlinecmdline.execute("scrapy crawl home" .split())ИНЩЯСНеХНсЙћЭМЁЃ 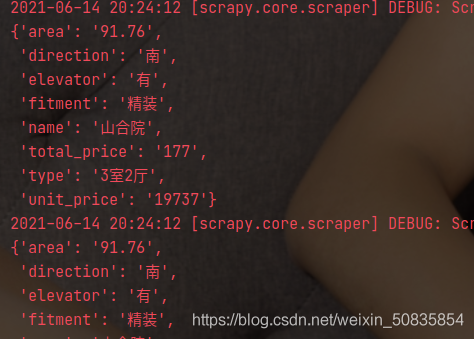
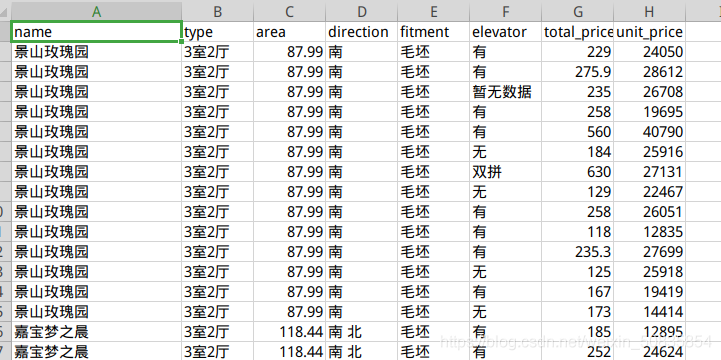
змНсДЫДЮЯюФПаТдіСЫМђЕЅЕФЪ§ОнЧхЯДЃЌдкећЬхЕФЪ§ОнзЅШЁЩЯУЛгадіМгаТЕФФбЖШЁЃ ЕНДЫетЦЊЙигкPython scrapyХРШЁЫежнЖўЪжЗПНЛвзЪ§ОнЕФЮФеТОЭНщЩмЕНетСЫ,ИќЖрЯрЙиscrapyХРШЁЖўЪжЗПНЛвзЪ§ОнФкШнЧыЫбЫї51zixue.netвдЧАЕФЮФеТЛђМЬајфЏРРЯТУцЕФЯрЙиЮФеТЯЃЭћДѓМввдКѓЖрЖржЇГж51zixue.netЃЁ
PythonжаpipЙЄОпЕФАВзАвдМАЪЙгУ
ЪЙгУPython pandasЖСШЁCSVЮФМўгІИУзЂвтЪВУД? |









