��ƪ�̳�OpenCV-Python ʵ������ͼƬ�Զ�ƴ�ӳ�ȫ��ͼд�ú�ʵ�ã�ϣ���ܰﵽ����
��������ͼƬ��ȫ��ƴ������Ѳ���ϡ�棬���ڵ�������������ֻ�����ͷ����������ͼƬ�Զ�ȫ��ƴ�ӵĹ��ܣ�����һ�㶼��Ҫ�������߱����豸��ƽ���Լ���������ƶ�ȡ����ʵ�ֽϺõ�ƴ�ӽ����������Ϊƴ�ӵ�ͼƬ֮�����Ҫ�����Ƶ������Ա�֤ƴ�ӽ����ȷ�Ժ������ԡ�������Ҫ����������� Python �� OpenCV ��ʵ������ͼƬ���Զ�ƴ�ϣ����ȼ���һ������ͼƬƴ�ӵ�ԭ����
����ԭ��Ҫʵ������ͼƬ�ļ�ƴ�ӣ���ʵֻ���ҳ�����ͼƬ�����Ƶĵ� (�����ĸ�����Ϊ homography ����ļ�����Ҫ�����ĸ���)�� ����һ��ͼƬ���Ա任����һ��ͼƬ�ı任���� (homography ��Ӧ�Ծ���)����������������ͼƬ�任��ŵ���һ��ͼƬ��Ӧ��λ�� ( �����൱�ڰ�����ͼƬ�ж��õ��ĸ����Ƶĵ�o�غ���һ��)����ˣ��Ϳ���ʵ�ּ�ȫ��ƴ�ӡ���Ȼ����Ϊƴ��֮��ͼƬ���ص���һ��������Ҫ���¼���ͼƬ�ص����ֵ�����ֵ������������ѿ��������ܽ�������ʵ���������裺 1. ������ͼƬ�����Ƶĵ㣬����任���� 2. �任һ��ͼƬ�ŵ���һ��ͼƬ���ʵ�λ�ã��������ص������µ�����ֵ (�������ͼƬ�ں�����Ҫ��ȡ�IJ���)
����ʵ��
Ѱ�����Ƶ���Ȼ�����ǿ����ֶ���Ѱ�����Ƶĵ㣬���������Ƚ��鷳����Ϊ���Ƶ�Խ��������Ƶ��Ӧ��λ��Խȷ�����õĽ����Խ�ã������˵��������ҵ�λ�����������ģ������ҳ��ܶ�ĵ�Ҳ����һ�������¡����Ծ��д�������������Զ�Ѱ�����Ƶ���㷨���������Ǿ����� SIFT �㷨���� OpenCV Ҳ�������ṩ SIFT �㷨�Ľӿڣ��������ǾͲ���Ҫ�Լ�����ȥʵ���ˡ����������Ų���ͼƬ��ԭͼ���ҳ����Ƶ���ͼƬ��  

���к�ɫ�ĵ��� SIFT �㷨�ҳ������Ƶ㣬����ɫ���߱�ʾ�����������ҳ������Ƶĵ�����ɸѡ���Ŀ��Ŷȸ��ߵ����Ƶĵ㡣��Ϊ�㷨�ҳ������Ƶ㲢��һ���ǰٷְ���ȷ�ġ�Ȼ��Ϳ��Ը�����Щɸѡ�������Ƶ����任����Ȼ OpenCV Ҳ�ṩ����Ӧ�Ľӿڷ������ǵļ��㣬������Ĵ���ʵ��Ҳ������ OpenCV �� Python tutorial ���ҵ� [1]��
ͼƬƴ��������任������������ǵڶ������ü�����ı任���������һ��ͼ���任��Ȼ��ѱ任��ͼƬ����һ��ͼƬ�ص���һ�𣬲����¼����ص������µ�����ֵ�����ڼ����ص����������ֵ����ʵ�����ж��ַ���ȥʵ��һ���õ��ں�Ч�������������ֱ��ĵ�Ч��Ҳ�����ķ�ʽ��ֱ����˵����ʵ��һ��ͼ������Խ��䣬�����ص�����������ߵIJ��֣������ͼ��������ʾ�Ķ�һЩ�������ұߵIJ��֣����ұ�ͼ���������ʾ�Ķ�һЩ���ù�ʽ��ʾ���ǣ����� alpha ��ʾ���ص�����굽�����ص�����߽������ľ��룬�µ�����ֵ��Ϊ newpixel = ��ͼ����ֵ �� (1 - alpha) + ��ͼ����ֵ �� alpha �������Ϳ���ʵ��һ�����ں�Ч���������ʵ�ָ����ӻ���õ�Ч��������ȥ�����ͳ���һ�� multi-band �ںϣ�����Ͳ��������ˡ������ʵ�ֵĽ���ʹ��룬�ɹ��ο��� 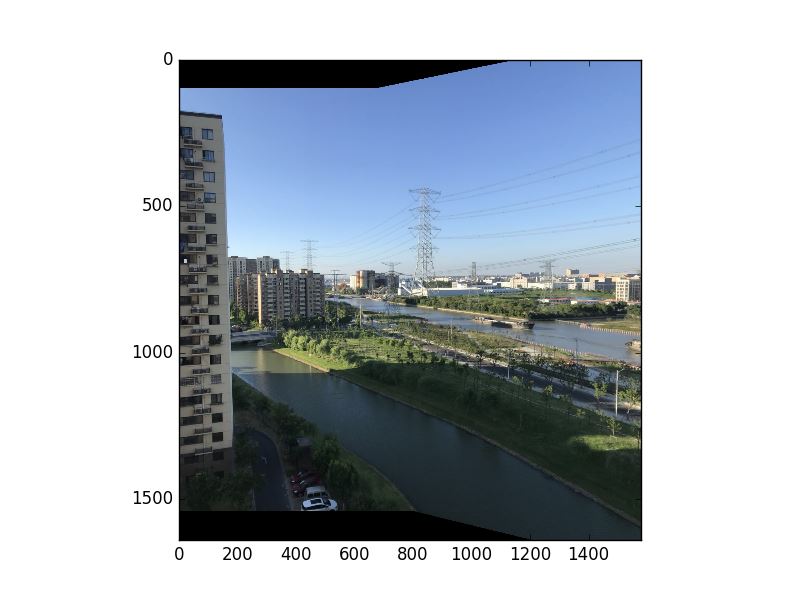
Python �������£� import numpy as npimport cv2 as cvfrom matplotlib import pyplot as pltif __name__ == '__main__': top, bot, left, right = 100, 100, 0, 500 img1 = cv.imread('test1.jpg') img2 = cv.imread('test2.jpg') srcImg = cv.copyMakeBorder(img1, top, bot, left, right, cv.BORDER_CONSTANT, value=(0, 0, 0)) testImg = cv.copyMakeBorder(img2, top, bot, left, right, cv.BORDER_CONSTANT, value=(0, 0, 0)) img1gray = cv.cvtColor(srcImg, cv.COLOR_BGR2GRAY) img2gray = cv.cvtColor(testImg, cv.COLOR_BGR2GRAY) sift = cv.xfeatures2d_SIFT().create() # find the keypoints and descriptors with SIFT kp1, des1 = sift.detectAndCompute(img1gray, None) kp2, des2 = sift.detectAndCompute(img2gray, None) # FLANN parameters FLANN_INDEX_KDTREE = 1 index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5) search_params = dict(checks=50) flann = cv.FlannBasedMatcher(index_params, search_params) matches = flann.knnMatch(des1, des2, k=2) # Need to draw only good matches, so create a mask matchesMask = [[0, 0] for i in range(len(matches))] good = [] pts1 = [] pts2 = [] # ratio test as per Lowe's paper for i, (m, n) in enumerate(matches): if m.distance < 0.7*n.distance: good.append(m) pts2.append(kp2[m.trainIdx].pt) pts1.append(kp1[m.queryIdx].pt) matchesMask[i] = [1, 0] draw_params = dict(matchColor=(0, 255, 0), singlePointColor=(255, 0, 0), matchesMask=matchesMask, flags=0) img3 = cv.drawMatchesKnn(img1gray, kp1, img2gray, kp2, matches, None, **draw_params) plt.imshow(img3, ), plt.show() rows, cols = srcImg.shape[:2] MIN_MATCH_COUNT = 10 if len(good) > MIN_MATCH_COUNT: src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2) dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2) M, mask = cv.findHomography(src_pts, dst_pts, cv.RANSAC, 5.0) warpImg = cv.warpPerspective(testImg, np.array(M), (testImg.shape[1], testImg.shape[0]), flags=cv.WARP_INVERSE_MAP) for col in range(0, cols): if srcImg[:, col].any() and warpImg[:, col].any(): left = col break for col in range(cols-1, 0, -1): if srcImg[:, col].any() and warpImg[:, col].any(): right = col break res = np.zeros([rows, cols, 3], np.uint8) for row in range(0, rows): for col in range(0, cols): if not srcImg[row, col].any(): res[row, col] = warpImg[row, col] elif not warpImg[row, col].any(): res[row, col] = srcImg[row, col] else: srcImgLen = float(abs(col - left)) testImgLen = float(abs(col - right)) alpha = srcImgLen / (srcImgLen + testImgLen) res[row, col] = np.clip(srcImg[row, col] * (1-alpha) + warpImg[row, col] * alpha, 0, 255) # opencv is bgr, matplotlib is rgb res = cv.cvtColor(res, cv.COLOR_BGR2RGB) # show the result plt.figure() plt.imshow(res) plt.show() else: print("Not enough matches are found - {}/{}".format(len(good), MIN_MATCH_COUNT)) matchesMask = None
Reference[1] OpenCV tutorial: https://docs.opencv.org/3.4.1/d1/de0/tutorial_py_feature_homography.html ������ƪ����OpenCV-Python ʵ������ͼƬ�Զ�ƴ�ӳ�ȫ��ͼ�����¾ͽ��ܵ�����,�������OpenCV ͼƬ�Զ�ƴ�ӳ�ȫ��ͼ����������51zixue.net��ǰ�����»�������������������ϣ������Ժ���֧��51zixue.net��
opencv-python+yolov3ʵ��Ŀ����
��Python��GIF��ͼ�ֽ�ɶ��ž�̬ͼƬ |



