етЦЊНЬГЬPythonЪ§ОнРраЭзюШЋжЊЪЖзмНсаДЕУКмЪЕгУЃЌЯЃЭћФмАяЕНФњЁЃ
вЛЁЂЪВУДЪЧЪ§ОнРраЭЦфЪЕПЩвдУїАзЪ§ОнРраЭжИЕФОЭЪЧБфСПжЕЕФВЛЭЌРраЭЃЌаеУћПЩФмЪЧвЛжжЪ§ОнРраЭЁЂФъСфПЩФмЪЧвЛжжЪ§ОнРраЭЁЂАЎКУПЩФмгжЪЧСэвЛжжЪ§ОнРраЭ
ЖўЁЂзжЗћДЎРраЭзжЗћДЎРраЭЫљБэЪОЕФЪ§ОнЪЧГЃСПЃЌЫќЪЧвЛжжВЛПЩБфЪ§ОнРраЭ
ШчКЮБэЪО str = 'zhangsan'str = "zhangsan"str = '''zhangsan''' # ПЩвдЪЕЯжЛЛааstr = """zhangsan""" # ПЩвдЪЕЯжЛЛааstr = r'zhangsan/n' # rПЩвдШЁЯћзЊвЦзжЗћЕФЙІФм ЯрЙиЗНЗЈ 
ОйР§ЃК find('str') # евВЛЕНЮЊ-1index('str') # евВЛЕНБЈДэisalnum('str') # гЩзжФИЛђЪ§зжзщГЩisspace('str') # гЩПеИёзщГЩsplit('str') # ЗжИюжЎКѓЪЧСаБэrsplit('str',2) # ЕБЗжИюДЮЪ§гаЯожЦЪБгыsplitгаЧјБ№partition('str') # ЗжИюжЎКѓЪЧШ§дЊзщcapitalize() # зжЗћДЎЪззжФИДѓаДtitle() # УПИіЕЅДЪЪззжФИДѓаДljust() # зѓЖдЦыМгПеИёШЁжЕгыЧаЦЌВйзї str = '123456789ЁЎ# ЯТБъШЁжЕstr[0] # 1str[-1] # 9# ЧаЦЌгяЗЈ m[start, end, step]str[1:3] # 23str[3:1] # Пеstr[0:] # 123456789str[:3] # 123str[::] # 123456789str[::-1] # 987654321str[0:4:1] # 1234str[0:4:2] # 13str[0:4:0] # БЈДэstr[0:4:-1] # Пеstr[4:0:-1] # 5432str[-3:-1] # 78str[-1:-3] # Пеstr[-3:-1:-1] # Пеstr[-3:-1:1] # 78str[-1:-3:-1] # 98str[-1:-3:1] # Пе БрТыгыНтТыВйзї chr(65) # БрТызЊЮЊзжЗћord('Юв') # зжЗћзЊЮЊБрТы'str'.encode('utf-8') # НЋзжЗћДЎзЊБрТы'str'.decode('utf-8') # НЋзжЗћДЎзЊНтТыИёЪНЛЏЪфГіВйзї ЦеЭЈИёЪНЛЏ %s(зжЗћДЎ)ЁЂ %d(ећаЮ)ЁЂ %f(ИЁЕуаЭ)ЁЂ %%(%)ЁЂ %x(ЪЎСљНјжЦ)ЁЂ %X(ЪЎСљНјжЦ)name = 'zhangsan'age = 18print('аеУћЃК', name, ',ФъСфЃК', age, sep='')print('аеУћЃК%s,ФъСфЃК%d' %(name,age))ЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊАцШЈЩљУїЃКБОЮФЮЊCSDNВЉжїЁИProChickЁЙЕФдДДЮФеТЃЌзёбCC 4.0 BY-SAАцШЈавщЃЌзЊдиЧыИНЩЯдЮФГіДІСДНгМАБОЩљУїЁЃдЮФСДНгЃКhttps://blog.csdn.net/qq_45747519/article/details/117379242formatИёЪНЛЏ # ФЌШЯprint('аеУћ{},ФъСф{}'.format('еХШ§',18))# ЯТБъИГжЕprint('аеУћ{1},ФъСф{0}'.format(18,'еХШ§'))# БфСПУћИГжЕprint('аеУћ{name},ФъСф{age}'.format(name='zhangsan',age=18))# СаБэИГжЕlist = ['zhangsan',18]print('аеУћ{},ФъСф{}'.format(*list))# зжЕфИГжЕdict = {"name":'zhangsan',"age":18}print('аеУћ{name},ФъСф{age}'.format(**dict))
Ш§ЁЂСаБэРраЭСаБэРраЭЫљДњБэЕФЪ§ОндЊЫигаађЧвПЩвджиИДЁЂПЩвдаоИФ
ШчКЮБэЪО mylist = ['еХШ§',18]mylist = list( ('zhangsan',18) ) # НЋПЩЕќДњЖдЯѓзЊЛЏЮЊСаБэЯрЙиЗНЗЈ ЬэМгдЊЫи list = [1,2,3]# зЗМгlist.append(4) # [1,2,3,4]# ВхШыlist.insert(0,0) # [0,1,2,3,4] аоИФдЊЫи list = [1,2,3]# аоИФжИЖЈЮЛжУдЊЫиlist[0] = 0 # [0,2,3]list[2] = 0 # [0,2,0] ЩОГ§дЊЫи list = [1,2,3,4,5,6]# ЩОГ§зюКѓвЛИіlist.pop() # [1,2,3,4,5]# ЩОГ§жИЖЈЮЛжУlist.pop(0) # [2,3,4,5]# ЩОГ§жИЖЈдЊЫиlist.remove(2) # [3,4,5]# ЧхПеlist.clear() # [] ВщбЏдЊЫи list = [1, 2, 3, 2, 1]# ВщевдЊЫиЮЛжУlist.index(1) # 0# ВщевдЊЫиИіЪ§list.count(1) # 2 КЯВЂСаБэ list1 = [1,2,3]list2 = [4,5,6]# КЯВЂlist1.extend(list2) # [1,2,3,4,5,6]print(list1+list2) # [1,2,3,4,5,6] ХХађ list = [2, 3, 1]# е§ађlist.sort() # [1,2,3]# ВњЩњаТЖдЯѓВЂе§ађnew_list = sorted(list) # [1,2,3]# ЕЙађlist.sort(reverse=True) # [3,2,1]# ЕЙађlist.reverse() # [3,2,1]# здЖЈвхХХађЙцдђ(вЛАугУгкзжЕфРраЭЕФБШНЯ)list = [ {'name':'zhangsan',age:18}, {'name':'lisi',age:20}, {'name':'wangwu',age:19}]list.sort(key = lambda item : item['age'])ПНБД list = [1, 2, 3]# ЪЧЧГПНБДnew_list = list.copy() # [1, 2, 3] ЧЖЬз # ЯрЕБгкЖўЮЌЪ§зщlist = [[1,2],[3,4],[5,6]] ЭЦЕМЪН list = [i for i in range(1,3)] # [1,2]list = [(i,j) for i in range(1,3) for j in range(1)] # [(1,0),(2,0)]
ЫФЁЂдЊзщРраЭдЊзщРраЭЫљБэЪОЕФЪ§ОндЊЫигаађЧвПЩвджиИДЃЌЕЋВЛПЩвдаоИФ
ШчКЮБэЪО # БэЪОЖрИідЊЫиtuple = (1,2,'3') # БэЪО1ИідЊЫиtuple = (True,) ЯрЙиЗНЗЈ ВщбЏдЊЫи tuple = (1,True,'3',True)tuple.index(0) # 1tuple.count(True) # 2 КЯВЂ tuple1 = (1,2)tuple2 = (True,False)print(tuple1+tuple2) # (1,2,True,False)
ЮхЁЂзжЕфРраЭзжЕфРраЭЫљБэЪОЕФЪ§ОндЊЫиЮоађЃЌKeyВЛПЩвджиИД(жЛФмЪЧВЛПЩБфЪ§ОнРраЭ)ЃЌValueПЩвдаоИФ(ПЩвдЮЊШЮвтЪ§ОнРраЭ)
ШчКЮБэЪО student = {"name":'zhangsan',"age":20} ЯрЙиЗНЗЈ ВщбЏдЊЫи student = {"name":'zhangsan',"age":20} print(student["age"]) # 20print(student["birth"]) # БЈДэprint(student.get("age")) # 20print(student.get("birth")) # Noneprint(student.get("birth",'2000-10-10')) # 2000-10-10d# ЛёШЁЫљгаKeyprint(student.keys()) # ['name','age']# ЛёШЁЫљгаValueprint(student.values()) # ['zhangsan',20]# ЛёШЁЫљгаKey-Valueprint(student.items()) # [('name':'zhangsan'),('age':20)]ЬэМгЁЂаоИФдЊЫи student = {"name":'zhangsan',"age":20} student["name"] = 'lisi'print(student) # student = {"name":'lisi',"age":20} student["sex"] = 'Фа'print(student) # student = {"name":'lisi',"age":20,"sex":'Фа'} ЩОГ§дЊЫи student = {"name":'zhangsan',"age":20} # ЩОГ§Key-ValueЃЌЗЕЛиValueresult = student.pop("name")print(student) # student = {"age":20} print(result) # zhangsan # ЩОГ§Key-ValueЃЌЗЕЛиKey-Valueresult = student.popitem("name")print(student) # student = {"age":20} print(result) # ('name','zhangsan') # ЧхПеstudent.clear()print(result) # {}КЯВЂ student = {"name":'zhangsan',"age":20} student_add = {"sex":'Фа'}student.update(student_add)print(student) # {"name":'zhangsan',"age":20,"sex":'Фа'} ЭЦЕМЪН student = {"name":'zhangsan',"age":20} student_reverse = {v:k for k,v in student.items()}print(student_reverse) # {"zhangsan":'name',"20":age}
СљЁЂМЏКЯРраЭМЏКЯРраЭЫљБэЪОЕФЪ§ОндЊЫиЮоађЧвВЛПЩвджиИДЃЌВЛПЩвдаоИФ
ШчКЮБэЪО # гадЊЫиЕФМЏКЯset = {1,'Юв',True} # ПеМЏКЯset()ЯрЙиЗНЗЈ ЬэМгдЊЫи set = {1,'Юв',True} set.add('zhangsan')print(set) # {1,'Юв',True,'zhangsan'} ЩОГ§дЊЫи set = {1,'Юв',True} # ЫцЛњЩОГ§вЛИідЊЫиset.pop()print(set) # {'Юв',True} # ЩОГ§жИЖЈдЊЫиset.remove('True')print(set) # {1,'Юв'} # ЧхПеset.clear()print(set) # set() КЯВЂ set = {1,'Юв',True} # СНИіМЏКЯКЯВЂКѓВњЩњаТЕФМЏКЯnew_set = set.union( {True,False} ) print(new_set) # {1,'Юв',True,False} # НЋвЛИіПЩЕќДњЖдЯѓКЯВЂЕНдгаМЏКЯжаset.update(['False'])print(set) # {1,'Юв',True,'False'} дЫЫу set1 = {1,2,3} set2 = {3,4,5}# ВюМЏprint(set1 - ste2) # {1,2}print(set2 - ste1) # {4,5}# НЛМЏprint(set1 & ste2) # {3}# ВЂМЏprint(set1 | ste2) # {1,2,3,4,5}# ВюВЂМЏprint(set1 ^ ste2) # {1,2,4,5}
ЦпЁЂЮхжжЪ§ОнРраЭЫљжЇГжЕФдЫЫуЗћБШНЯ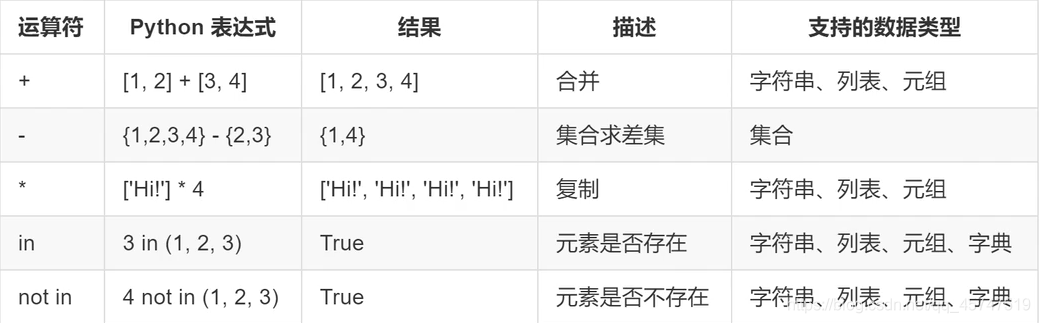
АЫЁЂЪ§ОнЕФађСаЛЏКЭЗДађСаЛЏађСаЛЏВйзї НЋЪ§ОнДгФкДцГжОУЛЏБЃДцЕНгВХЬЕФЙ§ГЬ
----(НЋЪ§ОнзЊЛЏЮЊзжЗћДЎ)----import jsonlist = ['name','age','city']file = open('test.txt','w',encoding='utf8')file.write(repr(list)) # ЕквЛжжЗНЪНfile.write(str(list)) # ЕкЖўжжЗНЪНfile.write(json.dumps(list)) # ЕкШ§жжЗНЪНjson.dump(list,file) # ЕкЫФжжЗНЪНfile.close()----(НЋЪ§ОнзЊЛЏЮЊЖўНјжЦ)----import picklelist = ['name','age','city']file = open('test.txt','wb',encoding='utf8')file.write(pickle.dumps(list)) # ЕквЛжжЗНЪНpickle.dump(list,file) # ЕкЖўжжЗНЪНfile.close()ЗДађСаЛЏВйзї НЋЪ§ОнДггВХЬМгдиЕНФкДцЕФЙ§ГЬ
# test.txt["name","age","city"] ----(НЋзжЗћДЎзЊЛЏЮЊЪ§Он)----import jsonfile = open('test.txt','r',encoding='utf8')list1 = json.load(file) # ЕквЛжжЗНЪНprint(list1) # ['name','age','city']list2 = json.loads(file.read()) # ЕкЖўжжЗНЪНprint(list2) # ['name','age','city']file.close()----(НЋЖўНјжЦзЊЛЏЮЊЪ§Он)----import picklefile = open('test.txt','rb',encoding='utf8')list1 = pickle.loads(file.read()) # ЕквЛжжЗНЪНprint(list1) # ['name','age','city']list2 = pickle.load(file) # ЕкЖўжжЗНЪНprint(list2) # ['name','age','city']file.close()ЕНДЫетЦЊЙигкPythonЪ§ОнРраЭзюШЋжЊЪЖзмНсЕФЮФеТОЭНщЩмЕНетСЫ,ИќЖрЯрЙиPythonЪ§ОнРраЭФкШнЧыЫбЫї51zixue.netвдЧАЕФЮФеТЛђМЬајфЏРРЯТУцЕФЯрЙиЮФеТЯЃЭћДѓМввдКѓЖрЖржЇГж51zixue.netЃЁ
НЬФудѕУДгУPythonВйзїMySqlЪ§ОнПт
TensorflowгыRNNЁЂЫЋЯђLSTMЕШЕФВШПгМЧТММАНтОі |

