这篇教程pytorch 实现多个Dataloader同时训练写得很实用,希望能帮到您。
看代码吧~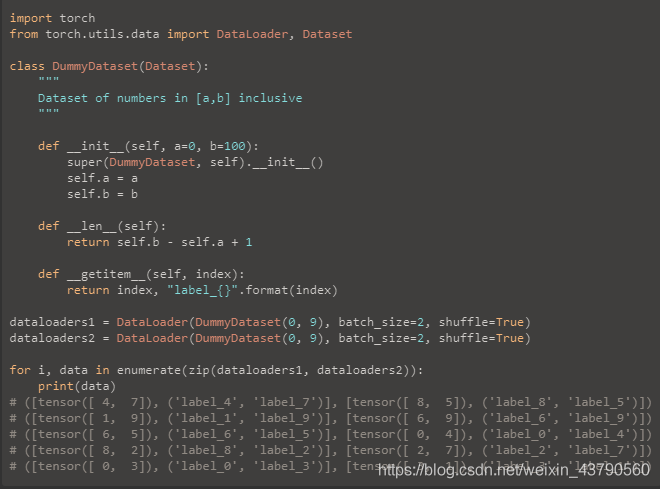
如果两个dataloader的长度不一样,那就加个: from itertools import cycle 仅使用zip,迭代器将在长度等于最小数据集的长度时耗尽。 但是,使用cycle时,我们将再次重复最小的数据集,除非迭代器查看最大数据集中的所有样本。 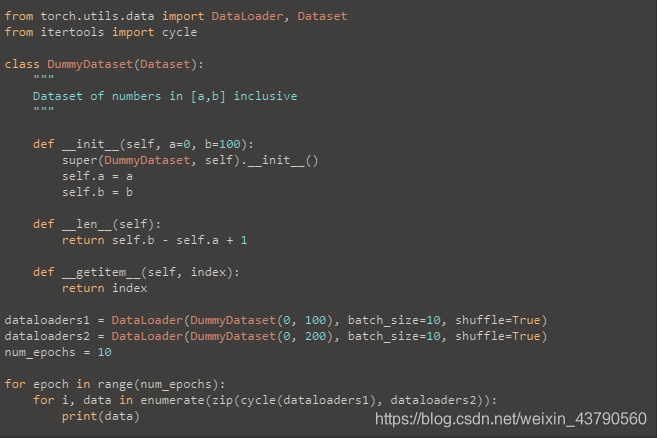
补充:pytorch技巧:自定义数据集 torch.utils.data.DataLoader 及Dataset的使用 本博客中有可直接运行的例子,便于直观的理解,在torch环境中运行即可。 1. 数据传递机制在 pytorch 中数据传递按一下顺序: 1、创建 datasets ,也就是所需要读取的数据集。 2、把 datasets 传入DataLoader。 3、DataLoader迭代产生训练数据提供给模型。 2. torch.utils.data.DatasetPytorch提供两种数据集:Map式数据集 Iterable式数据集。其中Map式数据集继承torch.utils.data.Dataset,Iterable式数据集继承torch.utils.data.IterableDataset。 本文只介绍 Map式数据集。一个Map式的数据集必须要重写 __getitem__(self, index)、 __len__(self) 两个方法,用来表示从索引到样本的映射(Map)。 __getitem__(self, index)按索引映射到对应的数据, __len__(self)则会返回这个数据集的长度。 基本格式如下: import torch.utils.data as dataclass VOCDetection(data.Dataset): ''' 必须继承data.Dataset类 ''' def __init__(self): ''' 在这里进行初始化,一般是初始化文件路径或文件列表 ''' pass def __getitem__(self, index): ''' 1. 按照index,读取文件中对应的数据 (读取一个数据!!!!我们常读取的数据是图片,一般我们送入模型的数据成批的,但在这里只是读取一张图片,成批后面会说到) 2. 对读取到的数据进行数据增强 (数据增强是深度学习中经常用到的,可以提高模型的泛化能力) 3. 返回数据对 (一般我们要返回 图片,对应的标签) 在这里因为我没有写完整的代码,返回值用 0 代替 ''' return 0 def __len__(self): ''' 返回数据集的长度 ''' return 0 可直接运行的例子: import torch.utils.data as dataimport numpy as npx = np.array(range(80)).reshape(8, 10) # 模拟输入, 8个样本,每个样本长度为10y = np.array(range(8)) # 模拟对应样本的标签, 8个标签 class Mydataset(data.Dataset): def __init__(self, x, y): self.x = x self.y = y self.idx = list() for item in x: self.idx.append(item) pass def __getitem__(self, index): input_data = self.idx[index] #可继续进行数据增强,这里没有进行数据增强操作 target = self.y[index] return input_data, target def __len__(self): return len(self.idx)datasets = Mydataset(x, y) # 初始化print(datasets.__len__()) # 调用__len__() 返回数据的长度for i in range(len(y)): input_data, target = datasets.__getitem__(i) # 调用__getitem__(index) 返回读取的数据对 print('input_data%d =' % i, input_data) print('target%d = ' % i, target)结果如下: 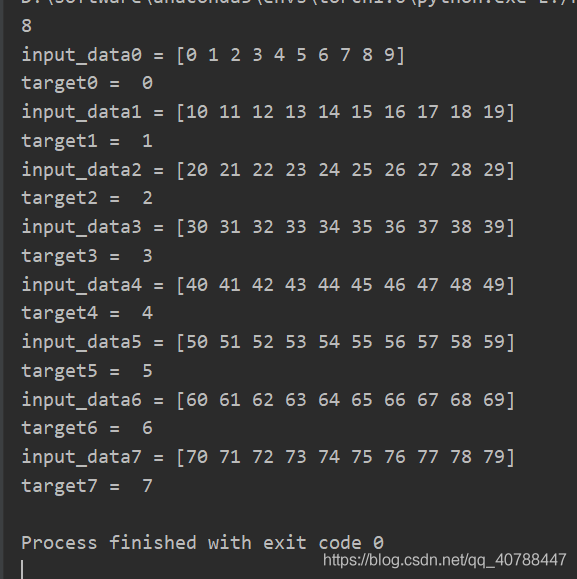
3. torch.utils.data.DataLoaderPyTorch中数据读取的一个重要接口是 torch.utils.data.DataLoader。 该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch_size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入。 torch.utils.data.DataLoader(onject)的可用参数如下: 1.dataset(Dataset): 数据读取接口,该输出是torch.utils.data.Dataset类的对象(或者继承自该类的自定义类的对象)。 2.batch_size (int, optional): 批训练数据量的大小,根据具体情况设置即可。一般为2的N次方(默认:1) 3.shuffle (bool, optional):是否打乱数据,一般在训练数据中会采用。(默认:False) 4.sampler (Sampler, optional):从数据集中提取样本的策略。如果指定,“shuffle”必须为false。我没有用过,不太了解。 5.batch_sampler (Sampler, optional):和batch_size、shuffle等参数互斥,一般用默认。 6.num_workers:这个参数必须大于等于0,为0时默认使用主线程读取数据,其他大于0的数表示通过多个进程来读取数据,可以加快数据读取速度,一般设置为2的N次方,且小于batch_size(默认:0) 7.collate_fn (callable, optional): 合并样本清单以形成小批量。用来处理不同情况下的输入dataset的封装。 8.pin_memory (bool, optional):如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存中. 9.drop_last (bool, optional): 如果数据集大小不能被批大小整除,则设置为“true”以除去最后一个未完成的批。如果“false”那么最后一批将更小。(默认:false) 10.timeout(numeric, optional):设置数据读取时间限制,超过这个时间还没读取到数据的话就会报错。(默认:0) 11.worker_init_fn (callable, optional): 每个worker初始化函数(默认:None) 可直接运行的例子: import torch.utils.data as dataimport numpy as npx = np.array(range(80)).reshape(8, 10) # 模拟输入, 8个样本,每个样本长度为10y = np.array(range(8)) # 模拟对应样本的标签, 8个标签class Mydataset(data.Dataset): def __init__(self, x, y): self.x = x self.y = y self.idx = list() for item in x: self.idx.append(item) pass def __getitem__(self, index): input_data = self.idx[index] target = self.y[index] return input_data, target def __len__(self): return len(self.idx)if __name__ ==('__main__'): datasets = Mydataset(x, y) # 初始化 dataloader = data.DataLoader(datasets, batch_size=4, num_workers=2) for i, (input_data, target) in enumerate(dataloader): print('input_data%d' % i, input_data) print('target%d' % i, target)结果如下:(注意看类别,DataLoader把数据封装为Tensor) 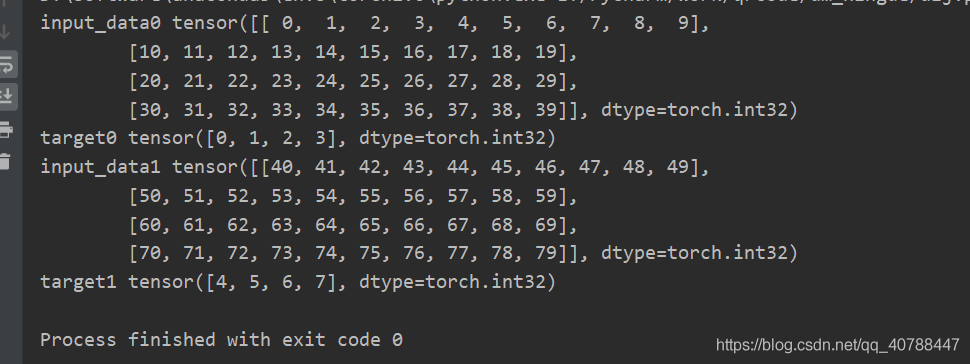
以上为个人经验,希望能给大家一个参考,也希望大家多多支持51zixue.net。
python 如何做一个识别率百分百的OCR
教你漂亮打印Pandas DataFrames和Series |



