етЦЊНЬГЬPyTorch ЪЕЯжL2е§дђЛЏвдМАDropoutЕФВйзїаДЕУКмЪЕгУЃЌЯЃЭћФмАяЕНФњЁЃ
СЫНтжЊЕРDropoutдРэШчЙћвЊЬсИпЩёОЭјТчЕФБэДяЛђЗжРрФмСІЃЌзюжБНгЕФЗНЗЈОЭЪЧВЩгУИќЩюЕФЭјТчКЭИќЖрЕФЩёОдЊЃЌИДдгЕФЭјТчвВвтЮЖзХИќМгШнвзЙ§ФтКЯЁЃ гкЪЧОЭгаСЫDropoutЃЌДѓВПЗжЪЕбщБэУїЦфОпгавЛЖЈЕФЗРжЙЙ§ФтКЯЕФФмСІЁЃ гУДњТыЪЕЯжDropout   
DropoutЕФnumpyЪЕЯж
PyTorchжаЪЕЯжdropout
import torch.nn.functional as Fimport torch.nn.init as initimport torchfrom torch.autograd import Variableimport matplotlib.pyplot as pltimport numpy as npimport math%matplotlib inline#%matplotlib inline ПЩвддкIpythonБрвыЦїРяжБНгЪЙгУ#ЙІФмЪЧПЩвдФкЧЖЛцЭМЃЌВЂЧвПЩвдЪЁТдЕєplt.show()етвЛВНЁЃxy=np.loadtxt('./data/diabetes.csv.gz',delimiter=',',dtype=np.float32)x_data=torch.from_numpy(xy[:,0:-1])#ШЁГ§СЫзюКѓвЛСаЕФЪ§Онy_data=torch.from_numpy(xy[:,[-1]])#ШЁзюКѓвЛСаЕФЪ§ОнЃЌ[-1]МгжаРЈКХЪЧЮЊСЫkeepdimprint(x_data.size(),y_data.size())#print(x_data.shape,y_data.shape)#НЈСЂЭјТчФЃаЭclass Model(torch.nn.Module): def __init__(self): super(Model,self).__init__() self.l1=torch.nn.Linear(8,60) self.l2=torch.nn.Linear(60,4) self.l3=torch.nn.Linear(4,1) self.sigmoid=torch.nn.Sigmoid() self.dropout=torch.nn.Dropout(p=0.5) def forward(self,x): out1=self.sigmoid(self.l1(x)) out2=self.dropout(out1) out3=self.sigmoid(self.l2(out2)) out4=self.dropout(out3) y_pred=self.sigmoid(self.l3(out4)) return y_pred #our modelmodel=Model()criterion=torch.nn.BCELoss(size_average=True)#optimizer=torch.optim.SGD(model.parameters(),lr=0.1)optimizer=torch.optim.Adam(model.parameters(),lr=0.1,weight_decay=0.1)#weight_decayЪЧL2е§дђ#training loopLoss=[]for epoch in range(2000): y_pred=model(x_data) loss=criterion(y_pred,y_data) if epoch%20 == 0: print("epoch = ",epoch," loss = ",loss.data) optimizer.zero_grad() loss.backward() optimizer.step() hour_var = Variable(torch.randn(1,8))print("predict",model(hour_var).data[0]>0.5)L2е§дђЛЏoptimizer=torch.optim.SGD(model.parameters(),lr=0.01,weight_decay=0.001) ВЙГфЃКPyTorch1.0ЪЕЯжL1ЃЌL2е§дђЛЏвдМАDropout (ИНdropoutдРэЕФpythonЪЕЯжвдМАИФНј) ПДДњТыАЩ~# Аќimport torchimport torch.nn as nnimport torch.nn.functional as F# torchvision АќЪеТМСЫШєИЩживЊЕФЙЋПЊЪ§ОнМЏЁЂЭјТчФЃаЭКЭМЦЫуЛњЪгОѕжаЕФГЃгУЭМЯёБфЛЛimport torchvisionimport torchvision.transforms as transforms import matplotlib.pyplot as pltimport numpy as np%matplotlib inline 1. ЪВУДЪЧdropoutЃЈЫцЛњЪЇЛюЃЉЃП1.1 вЛжжRegularizationЕФЗНЗЈгыL1ЁЂL2е§дђЛЏКЭзюДѓЗЖЪНдМЪјЕШЗНЗЈЛЅЮЊВЙГфЁЃдкбЕСЗЕФЪБКђЃЌdropoutЕФЪЕЯжЗНЗЈЪЧШУЩёОдЊвдГЌВЮЪ§ p ЕФИХТЪБЛМЄЛюЛђепБЛЩшжУЮЊ0ЁЃ 1.2 дкбЕСЗЙ§ГЬжаЫцЛњЪЇЛюПЩвдБЛШЯЮЊЪЧЖдЭъећЕФЩёОЭјТчГщбљГівЛаЉзгМЏЃЌУПДЮЛљгкЪфШыЪ§ОнжЛИќаТзгЭјТчЕФВЮЪ§ЃЈШЛЖјЃЌЪ§СПОоДѓЕФзгЭјТчУЧВЂВЛЪЧЯрЛЅЖРСЂЕФЃЌвђЮЊЫќУЧЖМЙВЯэВЮЪ§ЃЉЁЃ 1.3 дкВтЪдЙ§ГЬжаВЛЪЙгУЫцЛњЪЇЛюЫљгаЕФЩёОдЊЖММЄЛюЃЌ**ЕЋЪЧЖдгквўВуЕФЪфГіЖМвЊГЫвд p **ЁЃПЩвдРэНтЮЊЪЧЖдЪ§СПОоДѓЕФзгЭјТчУЧзіСЫФЃаЭМЏГЩЃЈmodel ensembleЃЉЃЌвдДЫРДМЦЫуГівЛИіЦНОљЕФдЄВтЁЃЯъМћЃКhttp://cs231n.github.io/neural-networks-2/ 1.4 вЛАудкШЋСЌНгВуАбЩёОдЊжУЮЊ0дкОэЛ§ВужаПЩФмАбФГИіЭЈЕРжУЮЊ0! 2. гУДњТыЪЕЯжregularization(L1ЁЂL2ЁЂDropoutЃЉзЂвтЃКPyTorchжаЕФregularizationЪЧдкoptimizerжаЪЕЯжЕФЃЌЫљвдЮоТлдѕУДИФБфweight_decayЕФДѓаЁЃЌlossЛсИњжЎЧАУЛгаМге§дђЯюЕФДѓаЁВюВЛЖрЁЃетЪЧвђЮЊloss_funЫ№ЪЇКЏЪ§УЛгаАбШЈжиWЕФЫ№ЪЇМгЩЯЃЁ 2.1 L1 regularizationЖдгкУПИі Іи ЮвУЧЖМЯђФПБъКЏЪ§діМгвЛИіІЫ|Іи| ЁЃ L1е§дђЛЏгавЛИігаШЄЕФаджЪЃЌЫќЛсШУШЈжиЯђСПдкзюгХЛЏЕФЙ§ГЬжаБфЕУЯЁЪшЃЈМДЗЧГЃНгНќ0ЃЉЁЃвВОЭЪЧЫЕЃЌЪЙгУL1е§дђЛЏЕФЩёОдЊзюКѓЪЙгУЕФЪЧЫќУЧзюживЊЕФЪфШыЪ§ОнЕФЯЁЪшзгМЏЃЌЭЌЪБЖдгкдывєЪфШыдђМИКѕЪЧВЛБфЕФСЫЁЃ ЯрНЯL1е§дђЛЏЃЌL2е§дђЛЏжаЕФШЈжиЯђСПДѓЖрЪЧЗжЩЂЕФаЁЪ§зжЁЃдкЪЕМљжаЃЌШчЙћВЛЪЧЬиБ№ЙизЂФГаЉУїШЗЕФЬиеїбЁдёЃЌвЛАуЫЕРДL2е§дђЛЏЖМЛсБШL1е§дђЛЏаЇЙћКУЁЃ PyTorchРяЕФoptimizerжЛФмЪЕЯжL2е§дђЛЏЃЌL1е§дђЛЏжЛФмЪжЖЏЪЕЯжЃК regularization_loss = 0for param in model.parameters(): regularization_loss += torch.sum(abs(param)) calssify_loss = criterion(pred,target)loss = classify_loss + lamda * regularization_lossoptimizer.zero_grad()loss.backward()optimizer.step() 2.2 L2 regularizationЖдгкЭјТчжаЕФУПИіШЈжи Іи ЃЌЯђФПБъКЏЪ§жадіМгвЛИі 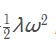 Цфжа ІЫ ЪЧе§дђЛЏЧПЖШЁЃетбљИУЪНзгЙигкЬнЖШОЭЪЧ ІЫІи СЫЁЃ Цфжа ІЫ ЪЧе§дђЛЏЧПЖШЁЃетбљИУЪНзгЙигкЬнЖШОЭЪЧ ІЫІи СЫЁЃ L2е§дђЛЏПЩвджБЙлРэНтЮЊЫќЖдгкДѓЪ§жЕЕФШЈжиЯђСПНјаабЯРїГЭЗЃЃЌЧуЯђгкИќМгЗжЩЂЕФШЈжиЯђСПЁЃ зюКѓашвЊзЂвтдкЬнЖШЯТНЕКЭВЮЪ§ИќаТЕФЪБКђЃЌЪЙгУL2е§дђЛЏвтЮЖзХЫљгаЕФШЈжиЖМвд w += -lambda * WЯђзХ0ЯпадЯТНЕЁЃ бЁдёвЛИіКЯЪЪЕФШЈжиЫЅМѕЯЕЪ§ІЫЗЧГЃживЊЃЌетИіашвЊИљОнОпЬхЕФЧщПіШЅГЂЪдЃЌГѕВНГЂЪдПЩвдЪЙгУ 1e-4 Лђеп 1e-3 дкPyTorchжаФГаЉoptimizerгХЛЏЦїЕФВЮЪ§weight_decay (float, optional)ОЭЪЧ L2 е§дђЯюЃЌЫќЕФФЌШЯжЕЮЊ0ЁЃ optimizer = torch.optim.SGD(model.parameters(),lr=0.01,weight_decay=0.001) 2.3 PyTorch1.0 ЪЕЯж dropoutЪ§ОнЩй, ВХФмЭЙЯдЙ§ФтКЯЮЪЬт, ЫљвдЮвУЧОЭзі10ИіЪ§ОнЕу. torch.manual_seed(1) # Sets the seed for generating random numbers.reproducibleN_SAMPLES = 20N_HIDDEN = 300# training datax = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)print('x.size()',x.size())# torch.normal(mean, std, out=None) Ёњ Tensory = x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))# test datatest_x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)test_y = test_x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))# show dataplt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')plt.legend(loc='upper left')plt.ylim((-2.5, 2.5))plt.show()x.size() torch.Size([20, 1]) 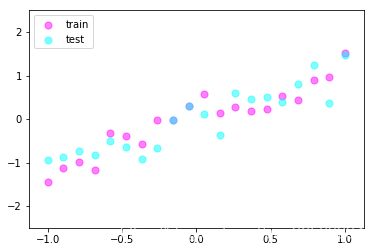
ЮвУЧЯждкДюНЈСНИіЩёОЭјТч, вЛИіУЛга dropout, вЛИіга dropout. УЛга dropout ЕФШнвзГіЯж Й§ФтКЯ, ФЧЮвУЧОЭУќУћЮЊ net_overfitting, СэвЛИіОЭЪЧ net_dropped. net_overfitting = torch.nn.Sequential( torch.nn.Linear(1,N_HIDDEN), torch.nn.ReLU(), torch.nn.Linear(N_HIDDEN,N_HIDDEN), torch.nn.ReLU(), torch.nn.Linear(N_HIDDEN,1),)net_dropped = torch.nn.Sequential( torch.nn.Linear(1,N_HIDDEN), torch.nn.Dropout(0.5), # 0.5ЕФИХТЪЪЇЛю torch.nn.ReLU(), torch.nn.Linear(N_HIDDEN,N_HIDDEN), torch.nn.Dropout(0.5), torch.nn.ReLU(), torch.nn.Linear(N_HIDDEN,1),) бЕСЗФЃаЭВЂВтЪд2ИіФЃаЭЕФperformance optimizer_ofit = torch.optim.Adam(net_overfitting.parameters(),lr=0.001)optimizer_drop = torch.optim.Adam(net_dropped.parameters(),lr=0.01)loss = torch.nn.MSELoss()for epoch in range(500): pred_ofit= net_overfitting(x) pred_drop= net_dropped(x) loss_ofit = loss(pred_ofit,y) loss_drop = loss(pred_drop,y) optimizer_ofit.zero_grad() optimizer_drop.zero_grad() loss_ofit.backward() loss_drop.backward() optimizer_ofit.step() optimizer_drop.step() if epoch%50 ==0 : net_overfitting.eval() # НЋЩёОЭјТчзЊЛЛГЩВтЪдаЮЪН,ДЫЪБВЛЛсЖдЩёОЭјТчdropout net_dropped.eval() # ДЫЪБВЛЛсЖдЩёОЭјТчdropout test_pred_ofit = net_overfitting(test_x) test_pred_drop = net_dropped(test_x) # show data plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train') plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test') plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(), 'r-', lw=3, label='overfitting') plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(), 'b--', lw=3, label='dropout(50%)') plt.text(0, -1.2, 'overfitting loss=%.4f' % loss(test_pred_ofit, test_y).data.numpy(), fontdict={'size': 20, 'color': 'red'}) plt.text(0, -1.5, 'dropout loss=%.4f' % loss(test_pred_drop, test_y).data.numpy(), fontdict={'size': 20, 'color': 'blue'}) plt.legend(loc='upper left') plt.ylim((-2.5, 2.5)) plt.pause(0.1) net_overfitting.train() net_dropped.train() plt.ioff()plt.show()вЛЙВ10еХЭМЦЌОЭВЛвЛвЛЗХЩЯРДСЫЃЌШЁ1,4,7,10еХАЩЃК 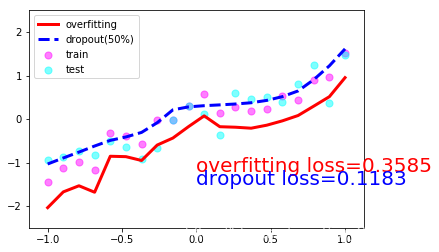 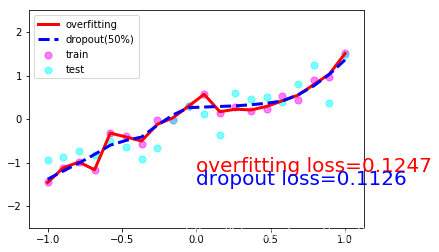 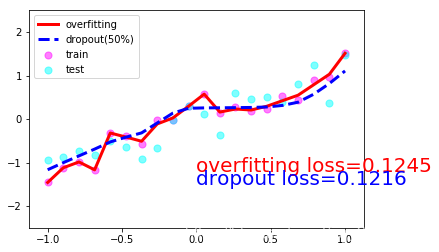 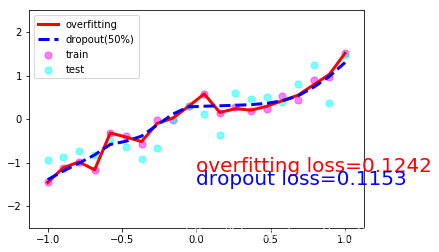
ЭјЩЯЖдгкЮЊЪВУДdropoutКѓвЊНјааrescaleЫѕЗХЕФЬжТлКмЖрЃЌетРяИјГіЫЙЬЙИЃcs231nПЮЩЯЕФНтЪЭЃЌИіШЫОѕЕУБШНЯгаЕРРэЃЌетРяЪЧЖдЦеЭЈdropoutЕФИФНјЃЌЪЙЕУЮоТлЪЧЗёЪЙгУЫцЛњЪЇЛюЃЌдЄВтЗНЗЈЕФДњТыПЩвдБЃГжВЛБфЁЃ вЛИі3ВуЩёОЭјТчЕФЦеЭЈАцdropoutПЩвдгУЯТУцДњТыЪЕЯжЃК """ ЦеЭЈАцЫцЛњЪЇЛю: ВЛЭЦМіЪЕЯж """p = 0.5 # МЄЛюЩёОдЊМЄЛюЩёОдЊМЄЛюЩёОдЊЃЈживЊЕФЪТЧщЫЕШ§БщЃЉЕФИХТЪ. pжЕИќИп = ЫцЛњЪЇЛюИќШѕdef train_step(X): """ XжаЪЧЪфШыЪ§Он """ # 3Вуneural networkЕФЧАЯђДЋВЅ H1 = np.maximum(0, np.dot(W1, X) + b1) U1 = np.random.rand(*H1.shape) < p # ЕквЛИіdropout mask H1 *= U1 # drop! H2 = np.maximum(0, np.dot(W2, H1) + b2) U2 = np.random.rand(*H2.shape) < p # ЕкЖўИіdropout mask H2 *= U2 # drop! out = np.dot(W3, H2) + b3 # ЗДЯђДЋВЅ:МЦЫуЬнЖШ... (Тд) # НјааВЮЪ§ИќаТ... (Тд) def predict(X):# ЧАЯђДЋВЅЪБФЃаЭМЏГЩH1 = np.maximum(0, np.dot(W1, X) + b1) * p # зЂвтЃКМЄЛюЪ§ОнвЊГЫвдpH2 = np.maximum(0, np.dot(W2, H1) + b2) * p # зЂвтЃКМЄЛюЪ§ОнвЊГЫвдpout = np.dot(W3, H2) + b3 ЩЯЪіВйзїВЛКУЕФаджЪЪЧБиаыдкВтЪдЪБЖдМЄЛюЪ§ОнвЊАДее p НјааЪ§жЕЗЖЮЇЕїећЃЌЮвУЧПЩвдЪЙЦфдкбЕСЗЪБОЭНјааЪ§жЕЗЖЮЇЕїећЃЌДгЖјШУЧАЯђДЋВЅдкВтЪдЪББЃГжВЛБфЁЃ етбљзіЛЙгавЛИіКУДІЃЌЮоТлФуОіЖЈЪЧЗёЪЙгУЫцЛњЪЇЛюЃЌдЄВтЗНЗЈЕФДњТыПЩвдБЃГжВЛБфЁЃетОЭЪЧЗДЯђЫцЛњЪЇЛюЃЈinverted dropoutЃЉЃК """inverted dropoutЃЈЗДЯђЫцЛњЪЇЛюЃЉ: ЭЦМіЪЕЯжЗНЪН.дкбЕСЗЕФЪБКђdropКЭЕїећЪ§жЕЗЖЮЇЃЌВтЪдЪБВЛгУШЮКЮИФБф."""p = 0.5 # МЄЛюЩёОдЊЕФИХТЪ. pжЕИќИп = ЫцЛњЪЇЛюИќШѕdef train_step(X): # 3Вуneural networkЕФЧАЯђДЋВЅ H1 = np.maximum(0, np.dot(W1, X) + b1) U1 = (np.random.rand(*H1.shape) < p) / p # ЕквЛИіdropout mask. зЂвт/p! H1 *= U1 # drop! H2 = np.maximum(0, np.dot(W2, H1) + b2) U2 = (np.random.rand(*H2.shape) < p) / p # ЕкЖўИіdropout mask. зЂвт/p! H2 *= U2 # drop! out = np.dot(W3, H2) + b3 # ЗДЯђДЋВЅ:МЦЫуЬнЖШ... (Тд) # НјааВЮЪ§ИќаТ... (Тд) def predict(X):# ЧАЯђДЋВЅЪБФЃаЭМЏГЩH1 = np.maximum(0, np.dot(W1, X) + b1) # ВЛгУЪ§жЕЗЖЮЇЕїећСЫH2 = np.maximum(0, np.dot(W2, H1) + b2)out = np.dot(W3, H2) + b3 вдЩЯЮЊИіШЫОбщЃЌЯЃЭћФмИјДѓМввЛИіВЮПМЃЌвВЯЃЭћДѓМвЖрЖржЇГж51zixue.netЁЃ
PythonПЊЗЂжЎQTНтОіЮоБпПђНчУцЭЯЖЏПЈЦСЮЪЬт(ИНДјдДТы)
Pytorch ШчКЮЪЕЯжГЃгУе§дђЛЏ |






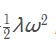 Цфжа ІЫ ЪЧе§дђЛЏЧПЖШЁЃетбљИУЪНзгЙигкЬнЖШОЭЪЧ ІЫІи СЫЁЃ
Цфжа ІЫ ЪЧе§дђЛЏЧПЖШЁЃетбљИУЪНзгЙигкЬнЖШОЭЪЧ ІЫІи СЫЁЃ



