��ƪ�̳̽��Pytorch��Batch Normalization layer�ȹ��Ŀ�д�ú�ʵ�ã�ϣ���ܰﵽ����
1. ע��momentum�Ķ���Pytorch�е�BN��Ķ���ƽ���ͳ����Ķ��������㷽ʽ���෴�ģ�Ĭ�ϵ�momentum=0.1 
BN����ı���ʽΪ�� 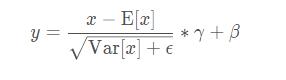
���Цúͦ��ǿ���ѧϰ�IJ�������Pytorch�У�BN�����IJ����У� CLASS torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ÿ���������庬��μ��ĵ�����Ҫע����ǣ�affine������BN��IJ����úͦ��Ƿ��ǿ�ѧϰ��(����ѧϰĬ���dz���1��0). 2. ע��BN���к���ͳ��������ֵ������ֵ�ͷ���track_running_stats �C a boolean value that when set to True, this module tracks the running mean and variance, and when set to False, this module does not track such statistics and always uses batch statistics in both training and eval modes. Default: True
��ѵ��������model.train()��train���̵�BN��ͳ����ֵ����ֵ�ͷ�����ͨ����ǰbatch���ݹ��Ƶġ� ���Ҳ���ʱ��model.eval()����track_running_stats=True��ģ�ʹ˿���ʹ�õ�ͳ��������Running status �еģ���ͨ��ָ��˥�������۵���ǰ����ֵ��������Ȼʹ�û��ڵ�ǰbatch���ݵĹ���ֵ�� 3. BN���ͳ�����ݸ�������ÿһ��ѵ����model.train()���forward()�������Զ�ʵ�ֵģ����������ݶȼ����뷴���и���optim.step()����� 4. ����BN����ͳ������������ķ������Կ���������ȷ�Ķ���BN�ķ�ʽ����ģ��ѵ��ʱ����BN����������������������״̬Ϊeval (��model.train()֮��training״̬��. ��������� You should use apply instead of searching its children, while named_children() doesn't iteratively search submodules.
def set_bn_eval(m): classname = m.__class__.__name__ if classname.find('BatchNorm') != -1: m.eval()model.apply(set_bn_eval)���ߣ���дmodule�е�train()������ def train(self, mode=True): """ Override the default train() to freeze the BN parameters """ super(MyNet, self).train(mode) if self.freeze_bn: print("Freezing Mean/Var of BatchNorm2D.") if self.freeze_bn_affine: print("Freezing Weight/Bias of BatchNorm2D.") if self.freeze_bn: for m in self.backbone.modules(): if isinstance(m, nn.BatchNorm2d): m.eval() if self.freeze_bn_affine: m.weight.requires_grad = False m.bias.requires_grad = False5. Fix/frozen Batch Norm when training may lead to RuntimeError: expected scalar type Half but found Float����취�� import torchimport torch.nn as nnfrom torch.nn import initfrom torchvision import modelsfrom torch.autograd import Variablefrom apex.fp16_utils import *def fix_bn(m): classname = m.__class__.__name__ if classname.find('BatchNorm') != -1: m.eval()model = models.resnet50(pretrained=True)model.cuda()model = network_to_half(model)model.train()model.apply(fix_bn) # fix batchnorminput = Variable(torch.FloatTensor(8, 3, 224, 224).cuda().half())output = model(input)output_mean = torch.mean(output)output_mean.backward()Please do def fix_bn(m): classname = m.__class__.__name__ if classname.find('BatchNorm') != -1: m.eval().half()Reason for this is, for regular training it is better (performance-wise) to use cudnn batch norm, which requires its weights to be in fp32, thus batch norm modules are not converted to half in network_to_half. However, cudnn does not support batchnorm backward in the eval mode , which is what you are doing, and to use pytorch implementation for this, weights have to be of the same type as inputs.
���䣺���ѧϰ�ܽ��pytorch��dropout��Batch Normalizationʱ��Ҫע��ĵط�����tensorflow��dropout��BNʱ��Ҫע��ĵط� ��pytorch��dropout��BNʱ��Ҫע��ĵط�pytorch��dropout: ����train��ʱ��ʹ��dropout,ѵ����ʱ��ʹ��dropout, pytorch������ͨ��net.eval()�̶�������������������������һЩǰ��IJ�����û��dropout��BN�����̶��������϶����е�validation set��Ҫʹ��net.eval() net.train()��ʾ�������ݶȵļ��㡣 net_dropped = torch.nn.Sequential( torch.nn.Linear(1, N_HIDDEN), torch.nn.Dropout(0.5), # drop 50% of the neuron torch.nn.ReLU(), torch.nn.Linear(N_HIDDEN, N_HIDDEN), torch.nn.Dropout(0.5), # drop 50% of the neuron torch.nn.ReLU(), torch.nn.Linear(N_HIDDEN, 1),)for t in range(500): pred_drop = net_dropped(x) loss_drop = loss_func(pred_drop, y) optimizer_drop.zero_grad() loss_drop.backward() optimizer_drop.step() if t % 10 == 0: # change to eval mode in order to fix drop out effect net_dropped.eval() # parameters for dropout differ from train mode test_pred_drop = net_dropped(test_x) # change back to train mode net_dropped.train() pytorch��Batch Normalization:net.eval()�̶���������������̶�BN�IJ�����moving_mean ��moving_var�������������ͼ: if self.do_bn: bn = nn.BatchNorm1d(10, momentum=0.5) setattr(self, 'bn%i' % i, bn) # IMPORTANT set layer to the Module self.bns.append(bn) for epoch in range(EPOCH): print('Epoch: ', epoch) for net, l in zip(nets, losses): net.eval() # set eval mode to fix moving_mean and moving_var pred, layer_input, pre_act = net(test_x) net.train() # free moving_mean and moving_var plot_histogram(*layer_inputs, *pre_acts) moving_mean ��moving_var
��tensorflow��dropout��BNʱ��Ҫע��ĵط�dropout��BN����һ��training�IJ�������������train����test, ����test��dropout���Dz�dropout��BN���ǹ̶�ס��BN�IJ����� tf_is_training = tf.placeholder(tf.bool, None) # to control dropout when training and testing# dropout netd1 = tf.layers.dense(tf_x, N_HIDDEN, tf.nn.relu)d1 = tf.layers.dropout(d1, rate=0.5, training=tf_is_training) # drop out 50% of inputsd2 = tf.layers.dense(d1, N_HIDDEN, tf.nn.relu)d2 = tf.layers.dropout(d2, rate=0.5, training=tf_is_training) # drop out 50% of inputsd_out = tf.layers.dense(d2, 1)for t in range(500): sess.run([o_train, d_train], {tf_x: x, tf_y: y, tf_is_training: True}) # train, set is_training=True if t % 10 == 0: # plotting plt.cla() o_loss_, d_loss_, o_out_, d_out_ = sess.run( [o_loss, d_loss, o_out, d_out], {tf_x: test_x, tf_y: test_y, tf_is_training: False} # test, set is_training=False )# pytorch def add_layer(self, x, out_size, ac=None): x = tf.layers.dense(x, out_size, kernel_initializer=self.w_init, bias_initializer=B_INIT) self.pre_activation.append(x) # the momentum plays important rule. the default 0.99 is too high in this case! if self.is_bn: x = tf.layers.batch_normalization(x, momentum=0.4, training=tf_is_train) # when have BN out = x if ac is None else ac(x) return out��BN��training�IJ���Ϊtrainʱ��ֻ�DZ�ʾBN�IJ����ǿɱ仯�ģ������Ǵ���BN���Լ�����moving_mean ��moving_var����Ϊ���������ǰ����µ�op,����train֮ǰ����ȷ��moving_mean ��moving_var�����ˣ�����moving_mean ��moving_var�IJ�����tf.GraphKeys.UPDATE_OPS # !! IMPORTANT !! the moving_mean and moving_variance need to be updated, # pass the update_ops with control_dependencies to the train_op update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) with tf.control_dependencies(update_ops): self.train = tf.train.AdamOptimizer(LR).minimize(self.loss) ����Ϊ���˾��飬ϣ���ܸ����һ���ο���Ҳϣ����Ҷ��֧��51zixue.net��
pytorch��LN(LayerNorm)��Relu���������������
ʹ��Gitee�Զ�������python�ű�����ϸ���� |