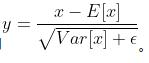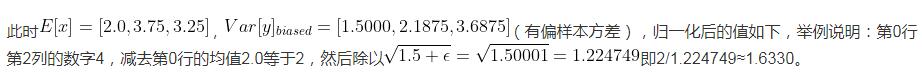这篇教程pytorch LayerNorm参数的用法及计算过程写得很实用,希望能帮到您。
说明LayerNorm中不会像BatchNorm那样跟踪统计全局的均值方差,因此train()和eval()对LayerNorm没有影响。 LayerNorm参数torch.nn.LayerNorm( normalized_shape: Union[int, List[int], torch.Size], eps: float = 1e-05, elementwise_affine: bool = True) normalized_shape如果传入整数,比如4,则被看做只有一个整数的list,此时LayerNorm会对输入的最后一维进行归一化,这个int值需要和输入的最后一维一样大。 假设此时输入的数据维度是[3, 4],则对3个长度为4的向量求均值方差,得到3个均值和3个方差,分别对这3行进行归一化(每一行的4个数字都是均值为0,方差为1);LayerNorm中的weight和bias也分别包含4个数字,重复使用3次,对每一行进行仿射变换(仿射变换即乘以weight中对应的数字后,然后加bias中对应的数字),并会在反向传播时得到学习。 如果输入的是个list或者torch.Size,比如[3, 4]或torch.Size([3, 4]),则会对网络最后的两维进行归一化,且要求输入数据的最后两维尺寸也是[3, 4]。 假设此时输入的数据维度也是[3, 4],首先对这12个数字求均值和方差,然后归一化这个12个数字;weight和bias也分别包含12个数字,分别对12个归一化后的数字进行仿射变换(仿射变换即乘以weight中对应的数字后,然后加bias中对应的数字),并会在反向传播时得到学习。 假设此时输入的数据维度是[N, 3, 4],则对着N个[3,4]做和上述一样的操作,只是此时做仿射变换时,weight和bias被重复用了N次。 假设此时输入的数据维度是[N, T, 3, 4],也是一样的,维度可以更多。 注意:显然LayerNorm中weight和bias的shape就是传入的normalized_shape。 eps归一化时加在分母上防止除零。 elementwise_affine如果设为False,则LayerNorm层不含有任何可学习参数。 如果设为True(默认是True)则会包含可学习参数weight和bias,用于仿射变换,即对输入数据归一化到均值0方差1后,乘以weight,即bias。 LayerNorm前向传播(以normalized_shape为一个int举例)1、如下所示输入数据的shape是(3, 4),此时normalized_shape传入4(输入维度最后一维的size),则沿着最后一维(沿着最后一维的意思就是对最后一维的数据进行操作) 并用这两个结果把batch沿着最后一维归一化,使其均值为0,方差为1。归一化公式用到了eps(),即 并用这两个结果把batch沿着最后一维归一化,使其均值为0,方差为1。归一化公式用到了eps(),即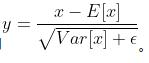 tensor = torch.FloatTensor([[1, 2, 4, 1], [6, 3, 2, 4], [2, 4, 6, 1]]) 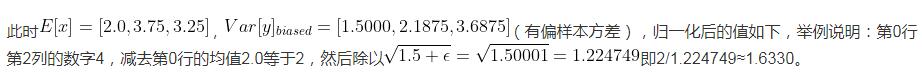
[[-0.8165, 0.0000, 1.6330, -0.8165], [ 1.5213, -0.5071, -1.1832, 0.1690], [-0.6509, 0.3906, 1.4321, -1.1717]] 2、如果elementwise_affine==True,则对归一化后的batch进行仿射变换,即乘以模块内部的weight(初值是[1., 1., 1., 1.])然后加上模块内部的bias(初值是[0., 0., 0., 0.]),这两个变量会在反向传播时得到更新。 3、如果elementwise_affine==False,则LayerNorm中不含有weight和bias两个变量,只做归一化,不会进行仿射变换。 总结在使用LayerNorm时,通常只需要指定normalized_shape就可以了。 补充:【Pytorch】F.layer_norm和nn.LayerNorm到底有什么区别? 背景最近在做视频方向,处理的是时序特征,就想着能不能用Batch Normalization来做视频特征BN层?在网上查阅资料发现,时序特征并不能用Batch Normalization,因为一个batch中的序列有长有短。 此外,BN 的一个缺点是需要较大的 batchsize 才能合理估训练数据的均值和方差,这导致内存很可能不够用,同时它也很难应用在训练数据长度不同的 RNN 模型上。 Layer Normalization (LN) 的一个优势是不需要批训练,在单条数据内部就能归一化。 对于RNN等时序模型,有时候同一个batch内部的训练实例长度不一(不同长度的句子),则不同的时态下需要保存不同的统计量,无法正确使用BN层,只能使用Layer Normalization。 查阅Layer Normalization(下述LN)后发现,这东西有两种用法,一个是F.layer_norm,一个是torch.nn.LayerNorm,本文探究他们的区别。 F.layer_norm用法F.layer_norm(x, normalized_shape, self.weight.expand(normalized_shape), self.bias.expand(normalized_shape)) 其中: x是输入的Tensor normalized_shape是要归一化的维度,可以是x的后若干维度 self.weight.expand(normalized_shape),可选参数,自定义的weight self.bias.expand(normalized_shape),可选参数,自定义的bias 示例很容易看出来,跟F.normalize基本一样,没有可学习的参数,或者自定义参数。具体使用示例如下: import torch.nn.functional as F input = torch.tensor(a)y = F.layer_norm(input,(4,))print(y) #####################输出################tensor([[[-0.8095, -1.1224, 1.2966, 0.6354], [-1.0215, -0.9661, 0.8387, 1.1488], [-0.3047, 1.0412, -1.4978, 0.7613]], [[ 0.4605, 1.2144, -1.5122, -0.1627], [ 1.5676, 0.1340, -1.0471, -0.6545], [ 1.5388, -0.3520, -1.2273, 0.0405]]]) 添加缩放: w = torch.tensor([1,1,2,2])b = torch.tensor([1,1,1,1])y = F.layer_norm(input,(4,),w,b)print(y) #########################输出######################tensor([[[ 0.1905, -0.1224, 3.5931, 2.2708], [-0.0215, 0.0339, 2.6775, 3.2976], [ 0.6953, 2.0412, -1.9956, 2.5225]], [[ 1.4605, 2.2144, -2.0243, 0.6746], [ 2.5676, 1.1340, -1.0942, -0.3090], [ 2.5388, 0.6480, -1.4546, 1.0810]]]) nn.LayerNorm用法torch.nn.LayerNorm( normalized_shape: Union[int, List[int], torch.Size], eps: float = 1e-05, elementwise_affine: bool = True) normalized_shape: 输入尺寸, [∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]] eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。 elementwise_affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。 示例elementwise_affine如果设为False,则LayerNorm层不含有任何可学习参数。 如果设为True(默认是True)则会包含可学习参数weight和bias,用于仿射变换,即对输入数据归一化到均值0方差1后,乘以weight,即bias。 import torchinput = torch.randn(2,3,2,2)import torch.nn as nn#取消仿射变换要写成#m = nn.LayerNorm(input.size()[1:], elementwise_affine=False)m1 = nn.LayerNorm(input.size()[1:])#input.size()[1:]为torch.Size([3, 2, 2])output1 = m1(input)#只normalize后两个维度m2 = nn.LayerNorm([2,2])output2 = m2(input)#只normalize最后一个维度m3 = nn.LayerNorm(2)output3 = m3(input) 总结F.layer_norm中没有可学习参数,而nn.LayerNorm有可学习参数。当elementwise_affine设为False时,nn.LayerNorm退化为F.layer_norm。 以上为个人经验,希望能给大家一个参考,也希望大家多多支持51zixue.net。
Python多线程与多进程相关知识总结
Python脚本文件外部传递参数的处理方法 |
 并用这两个结果把batch沿着最后一维归一化,使其均值为0,方差为1。归一化公式用到了eps(),即
并用这两个结果把batch沿着最后一维归一化,使其均值为0,方差为1。归一化公式用到了eps(),即