这篇教程python流水线框架pypeln的安装使用教程写得很实用,希望能帮到您。
1. 安装和入门使用安装pip install pypeln,基本元素如下: 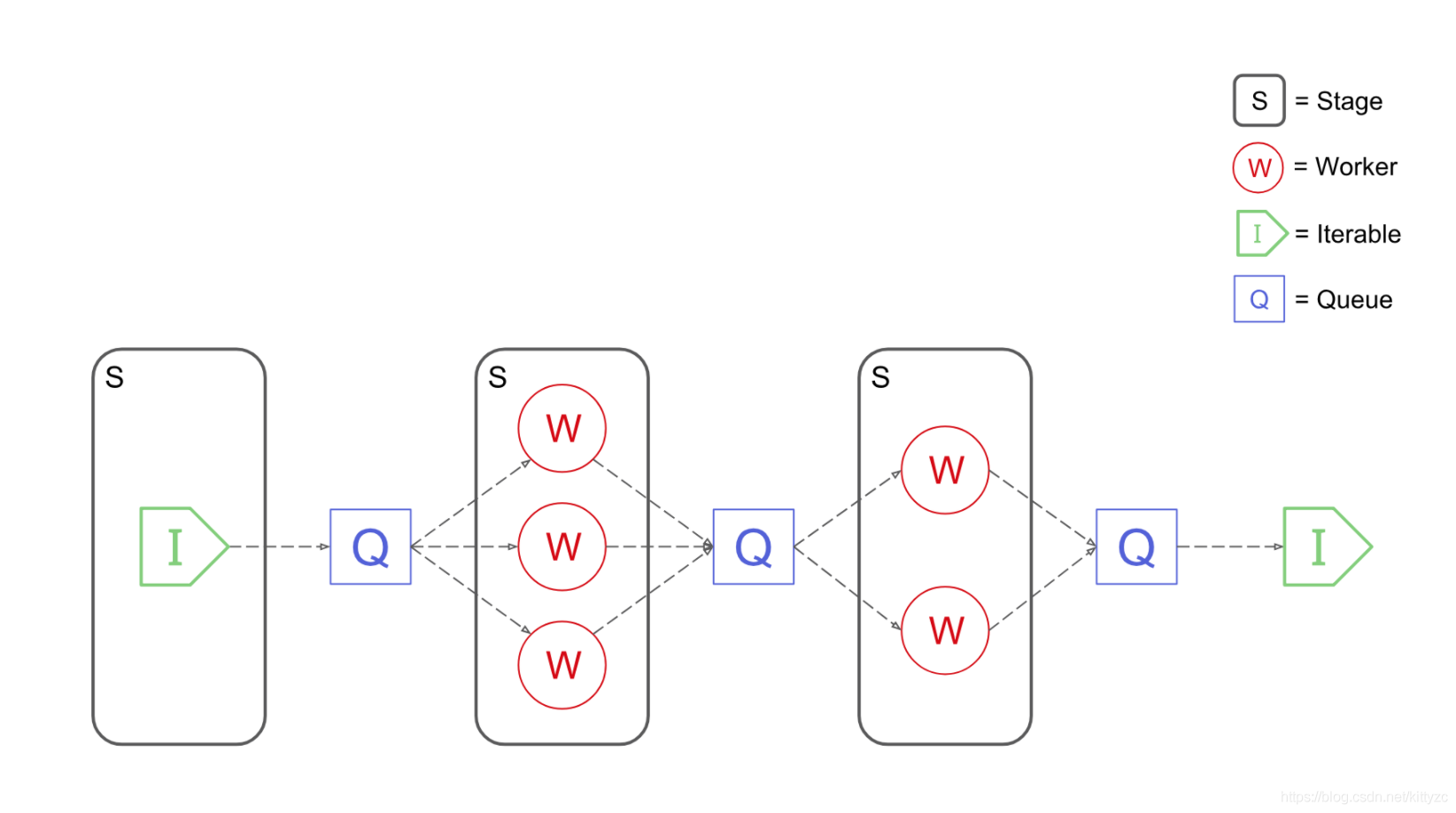
2 基于multiprocessing.Process这个是基于多进程。 import pypeln as plimport timefrom random import randomdef slow_add1(x): time.sleep(random()) # <= some slow computation return x + 1def slow_gt3(x): time.sleep(random()) # <= some slow computation return x > 3data = range(10) # [0, 1, 2, ..., 9] stage = pl.process.map(slow_add1, data, workers=3, maxsize=4)stage = pl.process.filter(slow_gt3, stage, workers=2)data = list(stage) # e.g. [5, 6, 9, 4, 8, 10, 7] 3 基于threading.Thread顾名思义,基于多线程。 import pypeln as plimport timefrom random import randomdef slow_add1(x): time.sleep(random()) # <= some slow computation return x + 1def slow_gt3(x): time.sleep(random()) # <= some slow computation return x > 3data = range(10) # [0, 1, 2, ..., 9] stage = pl.thread.map(slow_add1, data, workers=3, maxsize=4)stage = pl.thread.filter(slow_gt3, stage, workers=2)data = list(stage) # e.g. [5, 6, 9, 4, 8, 10, 7] 4 基于asyncio.Task协程,异步io。 import pypeln as plimport asynciofrom random import randomasync def slow_add1(x): await asyncio.sleep(random()) # <= some slow computation return x + 1async def slow_gt3(x): await asyncio.sleep(random()) # <= some slow computation return x > 3data = range(10) # [0, 1, 2, ..., 9] stage = pl.task.map(slow_add1, data, workers=3, maxsize=4)stage = pl.task.filter(slow_gt3, stage, workers=2)data = list(stage) # e.g. [5, 6, 9, 4, 8, 10, 7] 5 三者性能对比IO 密集型应用CPU等待IO时间远大于CPU 自身运行时间,太浪费;常见的 IO 密集型业务包括:浏览器交互、磁盘请求、网络爬虫、数据库请求等。
Python 世界对于 IO 密集型场景的并发提升有 3 种方法:多进程、多线程、异步 IO(asyncio)。理论上讲asyncio是性能最高的,原因如下:
1.进程、线程会有CPU上下文切换
2.进程、线程需要内核态和用户态的交互,性能开销大;而协程对内核透明的,只在用户态运行
3.进程、线程并不可以无限创建,最佳实践一般是 CPU*2;而协程并发能力强,并发上限理论上取决于操作系统IO多路复用(Linux下是 epoll)可注册的文件描述符的极限 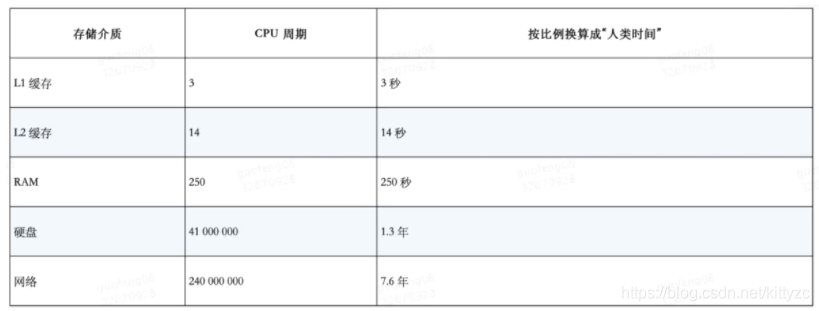
下面是一个数据库访问的测试: 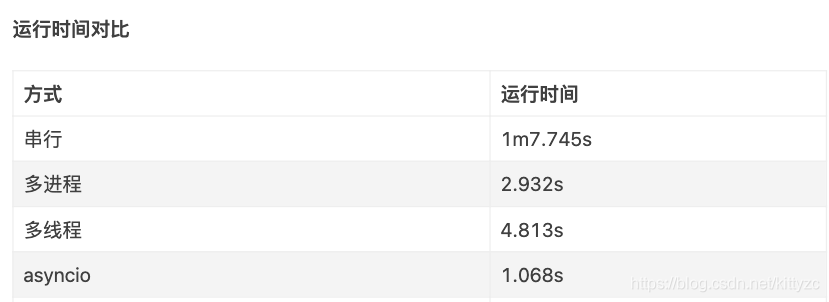
内存:
串行:75M
多进程:1.4G
多线程:150M
asyncio:120M 以上就是python流水线框架pypeln的安装使用教程的详细内容,更多关于python流水线框架的资料请关注51zixue.net其它相关文章!
解决Numpy与Pytorch彼此转换时的坑
在pytorch中计算准确率,召回率和F1值的操作 |


