这篇教程python基础之爬虫入门写得很实用,希望能帮到您。
前言python基础爬虫主要针对一些反爬机制较为简单的网站,是对爬虫整个过程的了解与爬虫策略的熟练过程。
爬虫分为四个步骤:请求,解析数据,提取数据,存储数据。本文也会从这四个角度介绍基础爬虫的案例。
一、简单静态网页的爬取我们要爬取的是一个壁纸网站的所有壁纸 http://www.netbian.com/dongman/
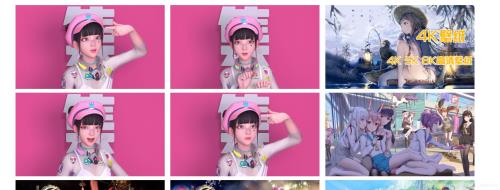
1.1 选取爬虫策略――缩略图首先打开开发者模式,观察网页结构,找到每一张图对应的的图片标签,可以发现我们只要获取到标黄的img标签并向它发送请求就可以得到壁纸的预览图了。 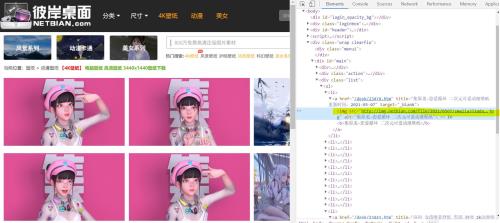
随后注意到网站不止一页,打开前3页的网站观察url有没有规律 http://www.netbian.com/dongman/index.htm#第一页http://www.netbian.com/dongman/index_2.htm#第二页http://www.netbian.com/dongman/index_3.htm#第三页 我们发现除了第一页其他页数的url都是有着固定规律的,所以先构建一个含有所有页数url的列表 url_start = 'http://www.netbian.com/dongman/'url_list=['http://www.netbian.com/dongman/index.htm']if not os.path.exists('./exercise'): os.mkdir('./exercise')for i in range(2,133): url = url_start+'index_'+str(i)+'.htm' url_list.append(url)至此我们的基本爬虫策略就确定了。 网页请求 for url in url_list: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' } response = requests.get(url=url,headers=headers).text解析数据 在这里我们选用etree解析数据 tree = etree.HTML(response) 提取数据 在这里我们选用xpath提取数据 leaf = tree.xpath('//div[@class="list"]//ul/li/a/img/@src')for l in leaf: print(l) h = requests.get(url=l, headers=headers).content存储数据 i = 'exercise/' + l.split('/')[-1]with open(i, 'wb') as fp: fp.write(h)完整代码 import requestsfrom lxml import etreeimport osurl_start = 'http://www.netbian.com/dongman/'url_list=['http://www.netbian.com/dongman/index.htm']#http://www.netbian.com/dongman/index_2.htmif not os.path.exists('./exercise'): os.mkdir('./exercise')for i in range(2,133): url = url_start+'index_'+str(i)+'.htm' url_list.append(url)print(url_list)for url in url_list: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' } response = requests.get(url=url,headers=headers).text tree = etree.HTML(response) leaf = tree.xpath('//div[@class="list"]//ul/li/a/img/@src') for l in leaf: print(l) h = requests.get(url=l, headers=headers).content i = 'exercise/' + l.split('/')[-1] with open(i, 'wb') as fp: fp.write(h)
1.2 选取爬虫策略――高清大图在刚刚的爬虫中我们爬取到的只是壁纸的缩略图,要想爬到高清版本,就需要我们更改策略。重新打开开发者工具进行观察,发现在原先爬取的img标签之上还有一个href标签,打开之后就会跳转高清大图。 
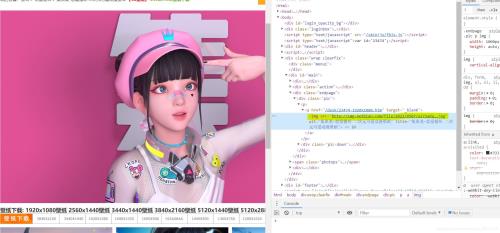
那么此时我们的爬取策略就变成了提取这个href标签的内容,向这个标签中的网站发送请求,随后在该网站中找到img标签进行再一次请求。 我们用到了正则表达式来提取href标签的内容。正则表达式是比xpath语法更简便的一种数据提取方法,具体有关语法可查看以下文档 for url in url_list: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' } response = requests.get(url=url,headers=headers).text leaf = re.findall("desk//d*.htm",response,re.S) for l in leaf: url = "http://www.netbian.com/"+str(l) h = requests.get(url=url, headers=headers).text leaf_ =re.findall('<div class="pic">.*?(http://img.netbian.com/file//d*//d*//w*.jpg)',h,re.S)这样输出的leaf_就是我们要找的高清大图的img标签,此时我们只需要再次发送请求随后再保存数据就可以了。 存储数据 for l_ in leaf_: print(l_) h = requests.get(url=l_, headers=headers).content i = 'exercise/' + l_.split('/')[-1] with open(i, 'wb') as fp: fp.write(h)完整代码 import requestsimport osimport reurl_start = 'http://www.netbian.com/dongman/'url_list=['http://www.netbian.com/dongman/index.htm']if not os.path.exists('./exercise'): os.mkdir('./exercise')for i in range(2,133): url = url_start+'index_'+str(i)+'.htm' url_list.append(url)print(url_list)for url in url_list: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' } response = requests.get(url=url,headers=headers).text leaf = re.findall("desk//d*.htm",response,re.S) for l in leaf: url = "http://www.netbian.com/"+str(l) h = requests.get(url=url, headers=headers).text leaf_ =re.findall('<div class="pic">.*?(http://img.netbian.com/file//d*//d*//w*.jpg)',h,re.S) for l_ in leaf_: print(l_) h = requests.get(url=l_, headers=headers).content i = 'exercise/' + l_.split('/')[-1] with open(i, 'wb') as fp: fp.write(h)
二、动态加载网站的爬取我们要爬取的是另一个壁纸网站的所有壁纸 https://sucai.gaoding.com/topic/9080?

2.1 选取爬虫策略――selenium首先打开开发者模式,观察网页结构,此时我们会发现一页上的所有壁纸并不是全部都加载出来了的,也就是说随着我们下拉滚动条,内容会不断实时加载出来,查看网页元素时也能看到lazy-image这个代表动态加载的标签。 
由于是动态加载,因此不能用之前的直接发送请求的办法来爬取数据了,面对这种情况我们就需要模拟浏览器发送一个请求,并且下拉页面,来实现爬取一个实时加载网页的目的。 观察完网页结构之后我们又来观察页数,这次就不多说了,想必大家也能发现规律 url_list=[]for i in range(1,4): url = 'https://sucai.gaoding.com/topic/9080?p={}'.format(i) url_list.append(url)网页请求 在这里我们用到了selenium这个自动化测试框架 for url in url_list: driver = webdriver.Chrome() driver.get(url) driver.maximize_window() time.sleep(2) i=0 while i<10:#下拉滚动条加载页面 i+=1 driver.execute_script("window.scrollBy(0,500)") driver.implicitly_wait(5)#显式等待解析提取数据 items = driver.find_elements_by_xpath("//*[@class='gdd-lazy-image__img gdd-lazy-image__img--loaded']") for item in items: href = item.get_attribute('src') print(href)至于数据的存储只需要再请求我们爬下来的href标签的网站就可以了。 完整代码 from selenium import webdriverimport timeimport osif not os.path.exists('./exercise'): os.mkdir('./exercise')headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36' }url_list=[]url_f_list=[]for i in range(1,4): url = 'https://sucai.gaoding.com/topic/9080?p={}'.format(i) url_list.append(url)for url in url_list: driver = webdriver.Chrome() driver.get(url) driver.maximize_window() time.sleep(2) i=0 while i<10: i+=1 driver.execute_script("window.scrollBy(0,500)") driver.implicitly_wait(5)#显式等待 items = driver.find_elements_by_xpath("//*[@class='gdd-lazy-image__img gdd-lazy-image__img--loaded']") for item in items: href = item.get_attribute('src') print(href)
2.2 选取爬虫策略――api众所周知,api接口是个好东西,如果找到了它,我们就无需担心动态加载,请求api返回给我们的是json格式的字典,里面或许有我们需要的东西也说不定。那么我们重新打开开发者工具搜索一番吧! 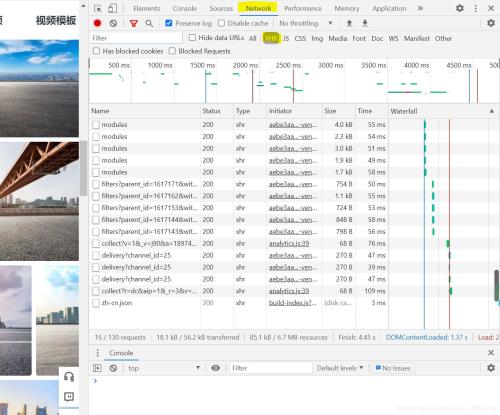
从Element切换到Network我们可以发现这里多了好多奇怪的东西,但是打开preview好像没有我们能用到的。 这个时候别灰心,切换下页面,等第二页加载出来的时候最后又多出来了一个xhr文件,点开preview我们惊喜的发现,这个里面有每一张图id的信息! 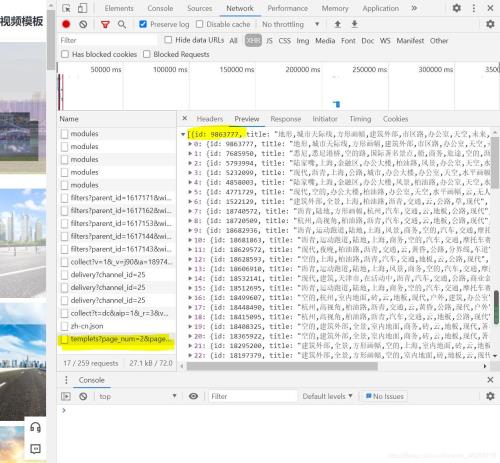
搜寻一圈发现字典里有效的只有id这个值,那么id对于我们的图片爬取有什么意义呢?通常情况下网址+id就可以定位到具体的图片,于是我点进去一张壁纸,惊喜的发现跟我想的一样! 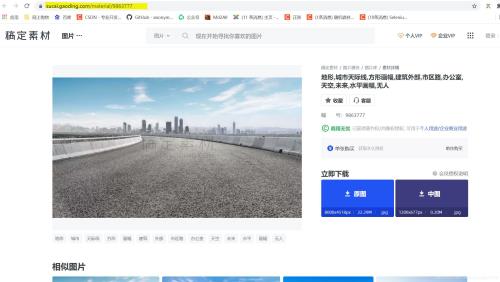
最后又到了我们老生常谈的页数环节,在看到这个api的request url之后大家有没有观察到它其中带着page_num=2&page_size=100这两个看着很像页码的参数呢?我们再往下就看到了参数中也正好有这两个值!也就是说我们只需要更改page_num=2就可以实现翻页了! 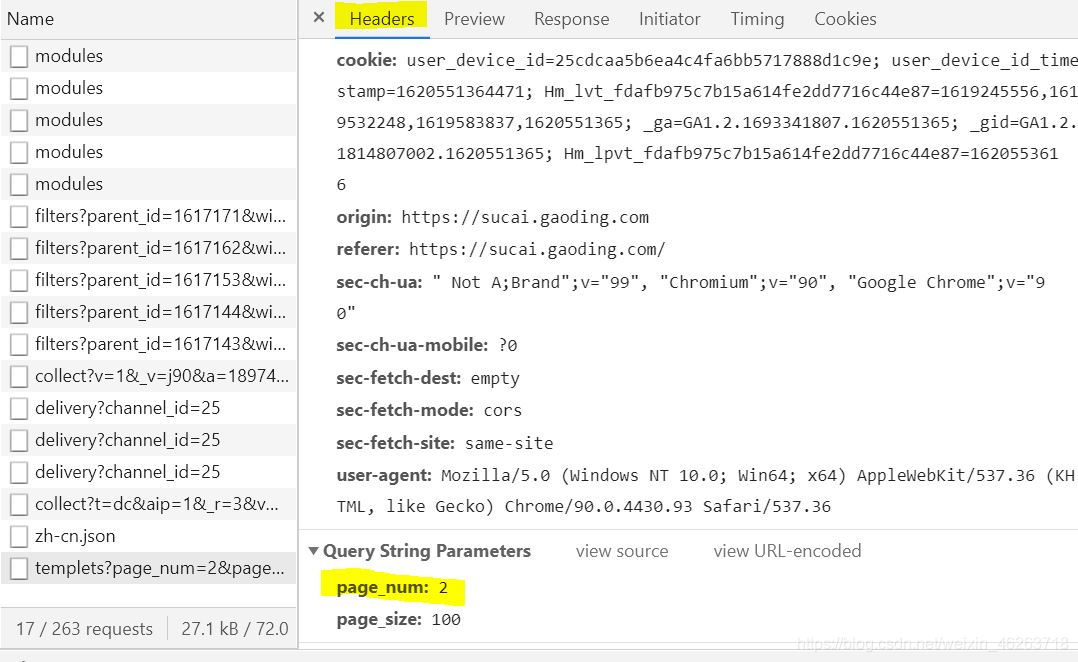
url='https://api-sucai.gaoding.com/api/csc-api/topics/9080/modules/18928/templets?'headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' }params_list=[]for i in range(1,4): parms ={ 'page_num': i, 'page_size': 100 } params_list.append(parms)解析提取数据 for param in params_list: response = requests.get(url=url,params=param,headers=headers).json() for i in range(100): try: dict =response[i] id = dict['id'] url_f = 'https://sucai.gaoding.com/material/'+str(id) url_f_list.append(url_f) except: pass 存储数据 for l in url_f_list: print(l) h = requests.get(url=l, headers=headers).content i = 'exercise/' + l.split('/')[-1] with open(i, 'wb') as fp: fp.write(h)完整代码 import osimport requestsif not os.path.exists('./exercise'): os.mkdir('./exercise')url='https://api-sucai.gaoding.com/api/csc-api/topics/9080/modules/18928/templets?'headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' }params_list=[]url_f_list=[]for i in range(1,4): parms ={ 'page_num': i, 'page_size': 100 } params_list.append(parms)for param in params_list: response = requests.get(url=url,params=param,headers=headers).json() for i in range(100): try: dict =response[i] id = dict['id'] url_f = 'https://sucai.gaoding.com/material/'+str(id) url_f_list.append(url_f) except: passfor l in url_f_list: print(l) #h = requests.get(url=l, headers=headers).content #i = 'exercise/' + l.split('/')[-1] #with open(i, 'wb') as fp: # fp.write(h)
三、selenium模拟登录我们要爬取的网站总是免不了登录这一关键环节,因此模拟登录也是一大爬虫基础。
我们要模拟登录的网站如下 https://www.icourse163.org/course/BIT-268001
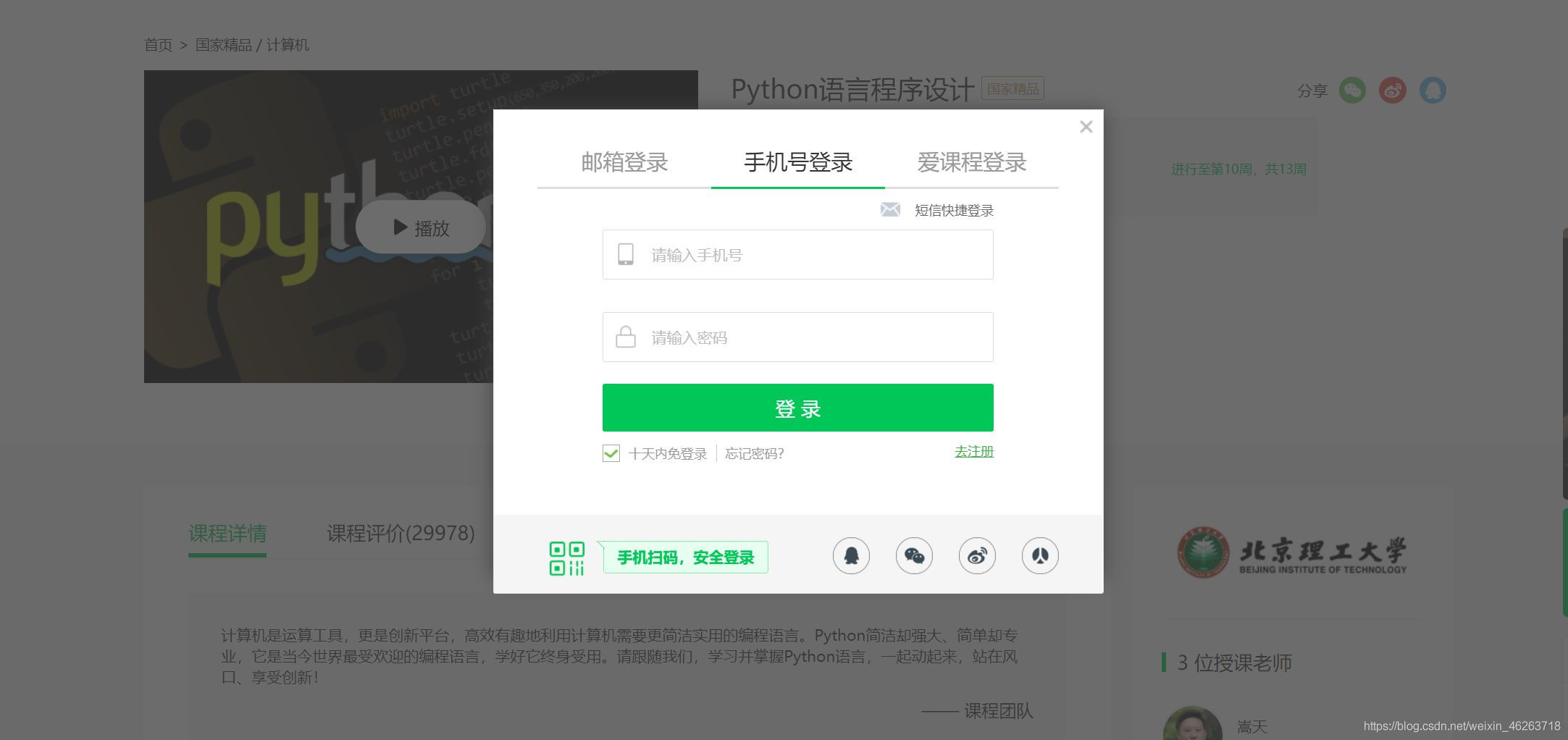
选取爬虫策略 既然我们是用selenium模拟登陆,首先肯定要明确我们要模拟的具体内容,归纳起来就是 点击 登录|注册
点击 其他登陆方式
点击 手机号登录
输入账号
输入密码
点击 登录
在明确该干些什么之后我们就打开开发者模式观察一下这个登录框吧。 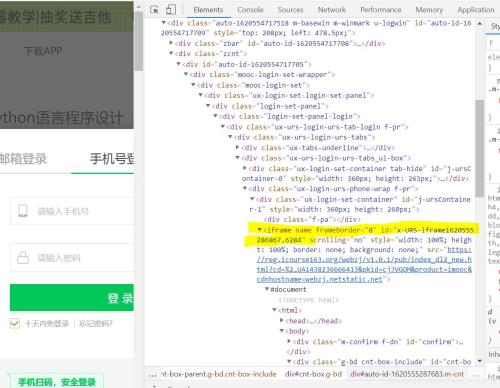
不看不知道,一看吓一跳,原来这里有一个iframe框架,这就意味着如果我们不做任何处理就查找元素的话可能会什么都查找不到。这就相当于在王家找李家的东西一样,我们首先需要切换到当前iframe driver.switch_to.frame(driver.find_element_by_xpath('//*[@id="j-ursContainer-1"]/iframe'))经过这一操作之后我们就可以正常按部就班的进行模拟登陆了! 完整代码 from selenium import webdriverimport timeurl = 'https://www.icourse163.org/course/BIT-268001'driver = webdriver.Chrome()driver.get(url)driver.maximize_window()#time.sleep(2)driver.find_element_by_xpath('//div[@class="unlogin"]/a').click()driver.find_element_by_class_name('ux-login-set-scan-code_ft_back').click()driver.find_element_by_xpath('//ul[@class="ux-tabs-underline_hd"]/li[2]').click()driver.switch_to.frame(driver.find_element_by_xpath('//*[@id="j-ursContainer-1"]/iframe'))driver.implicitly_wait(2)#给登录框一些加载的时间driver.find_element_by_css_selector('input[type="tel"]').send_keys('15201359153')driver.find_element_by_css_selector('input[class="j-inputtext dlemail"]').send_keys('Asdasd123')driver.implicitly_wait(2)#如果不等待的话可能密码还没输入结束就点按登录键了driver.find_element_by_id('submitBtn').click()到此这篇关于python基础之爬虫入门的文章就介绍到这了,更多相关python入门爬虫内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
python设置 matplotlib 正确显示中文的四种方式
Python批量将csv文件转化成xml文件的实例 |











