这篇教程Python实战之手写一个搜索引擎写得很实用,希望能帮到您。
一、前言这篇文章,我们将会尝试从零搭建一个简单的新闻搜索引擎 当然,一个完整的搜索引擎十分复杂,这里我们只介绍其中最为核心的几个模块 分别是数据模块、排序模块和搜索模块,下面我们会逐一讲解,这里先从宏观上看一下它们之间的工作流程
二、工作流程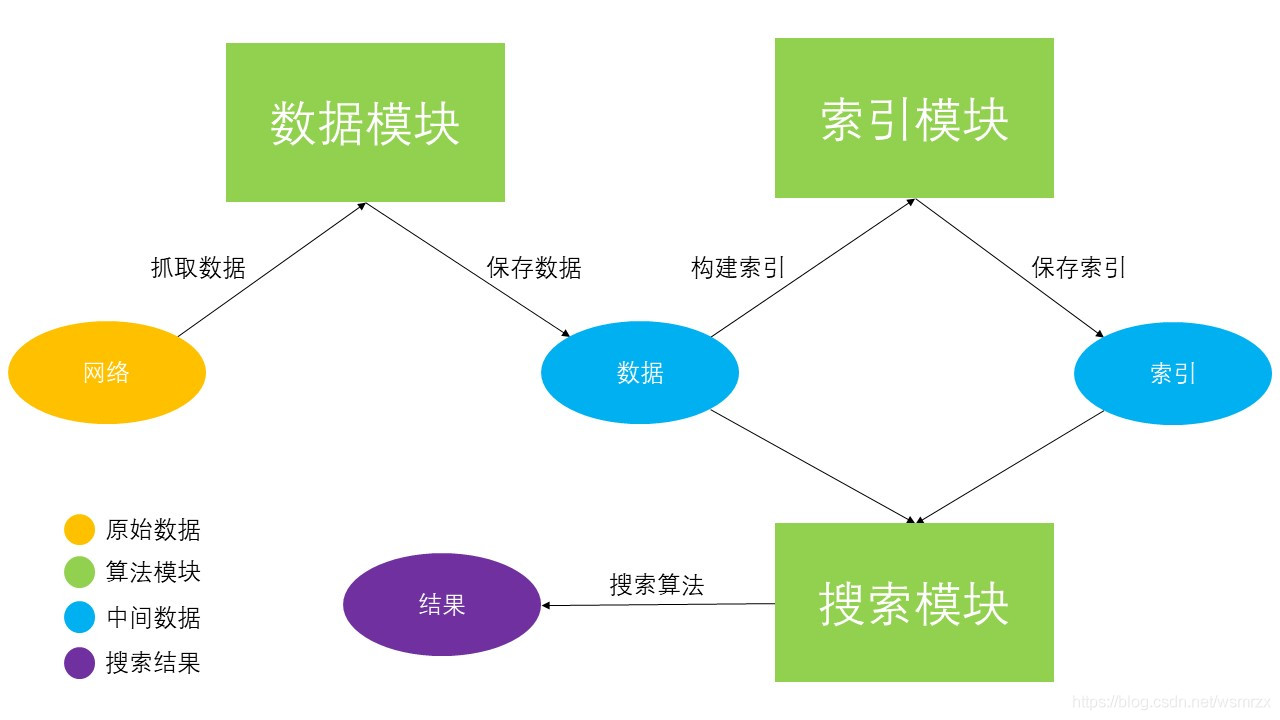
三、数据模块数据模块的主要作用是爬取网络上的数据,然后对数据进行清洗并保存到本地存储 一般来说,数据模块会采用非定向爬虫技术广泛爬取网络上的数据,以保证充足的数据源 但是由于本文只是演示,所以这里我们仅会采取定向爬虫爬取中国社会科学网上的部分文章素材 而且因为爬虫技术我们之前已经讲过很多,这里就不打算细讲,只是简单说明一下流程 首先我们定义一个数据模块类,名为 DataLoader,类中有一个核心变量 data 用于保存爬取下来的数据 以及两个相关的接口 grab_data (爬取数据) 和 save_data (保存数据到本地) grab_data() 的核心逻辑如下:
1.首先调用 get_entry(),获取入口链接 def get_entry(self): baseurl = 'http://his.cssn.cn/lsx/sjls/' entries = [] for idx in range(5): entry = baseurl if idx == 0 else baseurl + 'index_' + str(idx) + '.shtml' entries.append(entry) return entries 2.然后调用 parse4links(),遍历入口链接,解析得到文章链接 def parse4links(self, entries): links = [] headers = { 'USER-AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } for entry in entries: try: response = requests.get(url = entry, headers = headers) html = response.text.encode(response.encoding).decode('utf-8') time.sleep(0.5) except: continue html_parser = etree.HTML(html) link = html_parser.xpath('//div[@class="ImageListView"]/ol/li/a/@href') link_filtered = [url for url in link if 'www' not in url] link_complete = [entry + url.lstrip('./') for url in link_filtered] links.extend(link_complete) return links3.接着调用 parse4datas(),遍历文章链接,解析得到文章内容 def parse4datas(self, entries): datas = [] headers = { 'USER-AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } data_count = 0 for entry in entries: try: response = requests.get(url = entry, headers = headers) html = response.text.encode(response.encoding).decode('utf-8') time.sleep(0.2) except: continue html_parser = etree.HTML(html) title = html_parser.xpath('//span[@class="TitleFont"]/text()') content = html_parser.xpath('//div[@class="TRS_Editor"]//p//text()') content = [cont.replace('/u3000', '').replace('/xa0', '').replace('/n', '').replace('/t', '') for cont in content] content = [cont for cont in content if len(cont) > 30 and not re.search(r'[《|》]', cont)] if len(title) != 0 or len(content) != 0: data_count += 1 datas.append({ 'id' : data_count, 'link': entry, 'cont': '/t'.join(content), 'title': title[0] }) return datasgrab_data() 的核心代码如下:
def grab_data(self): # 获取入口链接 entries = self.get_entry() # 遍历入口链接,解析得到文章链接 links = self.parse4links(entries) # 遍历文章链接,解析得到文章内容 datas = self.parse4datas(links) # 将相关数据写入变量 data self.data = pd.DataFrame(datas) save_data() 的核心代码如下:
def save_data(self): # 将变量 data 写入 csv 文件 self.data.to_csv(self.data_path, index = None) 至此,我们已经爬取并保存好数据 data,数据以 DataFrame 形式存储,保存在 csv 文件,格式如下: |---------------------------------------------------|| id | link | cont | title ||---------------------------------------------------|| page id | page link | page content | page title ||---------------------------------------------------|| ...... | ...... | ...... | ...... ||---------------------------------------------------|
四、索引模块索引模型的主要作用是构建倒排索引 (inverted index),这是搜索引擎中十分关键的一环 一般来说,构建索引的目的就是为了提高查询速度 普通的索引一般是通过文章标识索引文章内容,而倒排索引则正好相反,通过文章内容索引文章标识 具体来说,倒排索引会以文章中出现过的词语作为键,以该词所在的文章标识作为值来构建索引 首先我们定义一个索引模块类,名为 IndexModel,类中有一个核心变量 iindex 用于保存倒排索引 以及两个相关的接口 make_iindex (构建索引) 和 save_iindex (保存索引到本地) make_iindex() 的核心代码如下(具体逻辑请参考注释):
def make_iindex(self): # 读取数据 df = pd.read_csv(self.data_path) # 特殊变量,用于搜索模块 TOTAL_DOC_NUM = 0 # 总文章数量 TOTAL_DOC_LEN = 0 # 总文章长度 # 遍历每一行 for row in df.itertuples(): doc_id = getattr(row, 'id') # 文章标识 cont = getattr(row, 'cont') # 文章内容 TOTAL_DOC_NUM += 1 TOTAL_DOC_LEN += len(cont) # 对文章内容分词 # 并将其变成 {word: frequency, ...} 的形式 cuts = jieba.lcut_for_search(cont) word2freq = self.format(cuts) # 遍历每个词,将相关数据写入变量 iindex for word in word2freq: meta = { 'id': doc_id, 'dl': len(word2freq), 'tf': word2freq[word] } if word in self.iindex: self.iindex[word]['df'] = self.iindex[word]['df'] + 1 self.iindex[word]['ds'].append(meta) else: self.iindex[word] = {} self.iindex[word]['df'] = 1 self.iindex[word]['ds'] = [] self.iindex[word]['ds'].append(meta) # 将特殊变量写入配置文件 self.config.set('DATA', 'TOTAL_DOC_NUM', str(TOTAL_DOC_NUM)) # 文章总数 self.config.set('DATA', 'AVG_DOC_LEN', str(TOTAL_DOC_LEN / TOTAL_DOC_NUM)) # 文章平均长度 with open(self.option['filepath'], 'w', encoding = self.option['encoding']) as config_file: self.config.write(config_file)save_iindex() 的核心代码如下:
def save_iindex(self): # 将变量 iindex 写入 json 文件 fd = open(self.iindex_path, 'w', encoding = 'utf-8') json.dump(self.iindex, fd, ensure_ascii = False) fd.close() 至此,我们们经构建并保存好索引 iindex,数据以 JSON 形式存储,保存在 json 文件,格式如下: { word: { 'df': document_frequency, 'ds': [{ 'id': document_id, 'dl': document_length, 'tf': term_frequency }, ...] }, ...}
五、搜索模块在得到原始数据和构建好倒排索引后,我们就可以根据用户的输入查找相关的内容 具体怎么做呢? 1.首先我们对用户的输入进行分词 2.然后根据倒排索引获取每一个词相关的文章 3.最后计算每一个词与相关文章之间的得分,得分越高,说明相关性越大 这里我们定义一个搜索模块类,名为 SearchEngine,类中有一个核心函数 search 用于查询搜索 def search(self, query): BM25_scores = {} # 对用户输入分词 # 并将其变成 {word: frequency, ...} 的形式 query = jieba.lcut_for_search(query) word2freq = self.format(query) # 遍历每个词 # 计算每个词与相关文章之间的得分(计算公式参考 BM25 算法) for word in word2freq: data = self.iindex.get(word) if not data: continue BM25_score = 0 qf = word2freq[word] df = data['df'] ds = data['ds'] W = math.log((self.N - df + 0.5) / (df + 0.5)) for doc in ds: doc_id = doc['id'] tf = doc['tf'] dl = doc['dl'] K = self.k1 * (1 - self.b + self.b * (dl / self.AVGDL)) R = (tf * (self.k1 + 1) / (tf + K)) * (qf * (self.k2 + 1) / (qf + self.k2)) BM25_score = W * R BM25_scores[doc_id] = BM25_scores[doc_id] + BM25_score if doc_id in BM25_scores else BM25_score # 对所有得分按从大到小的顺序排列,返回结果 BM25_scores = sorted(BM25_scores.items(), key = lambda item: item[1]) BM25_scores.reverse() return BM25_scores到此这篇关于Python实战之手写一个搜索引擎的文章就介绍到这了,更多相关Python写搜索引擎内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
pygame多种方式实现屏保操作(自动切换、鼠标切换、键盘切换)
Python数据分析之彩票的历史数据 |
