这篇教程Python爬虫基础之requestes模块写得很实用,希望能帮到您。
一、爬虫的流程开始学习爬虫,我们必须了解爬虫的流程框架。在我看来爬虫的流程大概就是三步,即不论我们爬取的是什么数据,总是可以把爬虫的流程归纳总结为这三步: 1.指定 url,可以简单的理解为指定要爬取的网址 2.发送请求。requests 模块的请求一般为 get 和 post 3.将爬取的数据存储
二、requests模块的导入因为 requests 模块属于外部库,所以需要我们自己导入库 导入的步骤: 1.右键Windows图标 2.点击“运行” 3.输入“cmd”打开命令面板 4.输入“pip install requests”,等待下载完成 如图: 
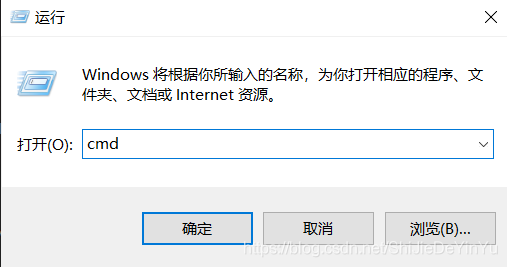

如果还是下载失败,我的建议是百度一下,你就知道(我也是边学边写,是在是水平有限) 欧克,既然导入成功后我们就简单的来爬取一下搜狗的首页吧!
三、完整代码import requestsif __name__ == "__main__": # 指定url url = "https://www.sougou.com/" # 发起请求 # get方法会返回一个响应数据 response = requests.get(url) # 获取响应数据 page_txt = response.text # text返回一个字符串的响应数据 # print(page_txt) # 存储 with open("./sougou.html", "w", encoding = "utf-8") as fp: fp.write(page_txt) print("爬取数据结束!!!")我们打开保存的文件,如图 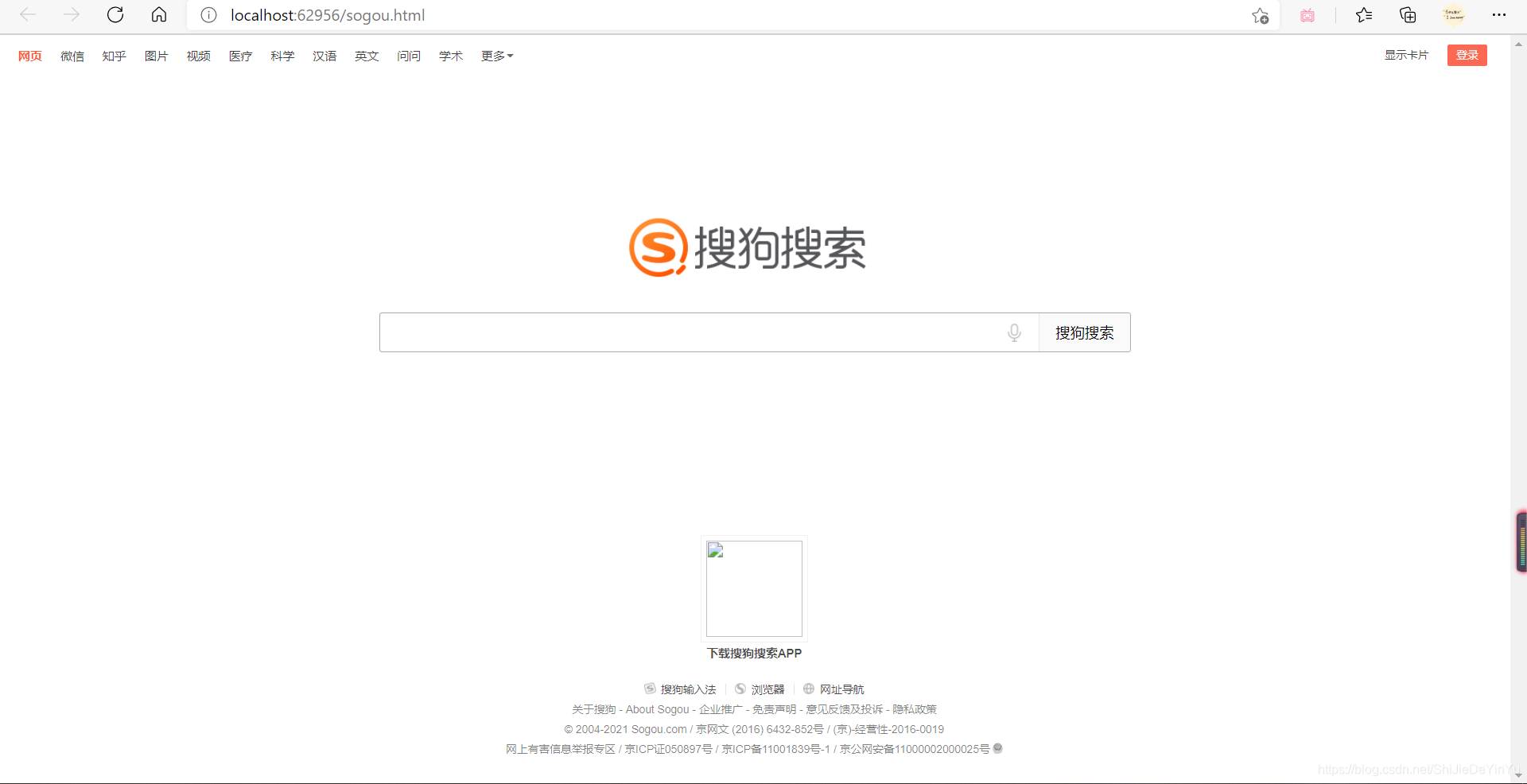
欧克,这就是最基本的爬取,如果学会了,那就试一试爬取 B站 的首页吧。 到此这篇关于Python爬虫基础之requestes模块的文章就介绍到这了,更多相关Python requestes模块内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
Django利用Cookie实现反爬虫的例子
python爬虫基础之简易网页搜集器 |



