ХвЖӘҪМіМpython numpyЦРsetdiff1dөДУГ·ЁЛөГчРҙөГәЬКөУГЈ¬ПЈНыДЬ°пөҪДъЎЈ
Т»ЎўәҜКэҪвКНsetdiff1d(ar1, ar2, assume_unique=False) 1.№ҰДЬЈәХТөҪ2ёцКэЧйЦРјҜәПФӘЛШөДІоТмЎЈ 2.·ө»ШЦөЈәФЪar1ЦРө«І»ФЪar2ЦРөДТСЕЕРтөДОЁТ»ЦөЎЈ 3.ІОКэЈә ar1Јәarray_like КдИлКэЧйЎЈ ar2Јәarray_like КдИлұИҪПКэЧйЎЈ assume_uniqueЈәboolЎЈИз№ыОӘTrueЈ¬ФтјЩ¶ЁКдИлКэЧйКЗОЁТ»өДЈ¬јҙҝЙТФјУҝмјЖЛгЛЩ¶ИЎЈ Д¬ИПЦөОӘFalseЎЈ ¶юЎўҫЯМеКҫАэ1.assume_unique = FalseөДЗйҝцЈә a = np.array([1,2,3]) b = np.array([4,5,6]) c = np.setdiff1d(a, b) print(c)#[1 2 3] a = np.array([1,2,3]) b = np.array([1,2,3]) c = np.setdiff1d(a, b) print(c)#[] a = np.array([1,2,3]) b = np.array([2,3,4]) c = np.setdiff1d(a, b) print(c)#[1] a = np.array([1,2,3,4]) b = np.array([3,4,5,6]) c = np.setdiff1d(a, b) print(c)#[1 2] a = np.array([1,2,3,2,4,1]) b = np.array([3,4,5,6]) c = np.setdiff1d(a, b) print(c)#[1 2] a = np.array([8,2,3,2,4,1]) b = np.array([7,4,5,6,3]) c = np.setdiff1d(a, b) print(c)#[1 2 8] ҝЙТФҙУЧоәуҝҙіц·ө»ШөДЦөҙУРЎөҪҙуЕЕРтЈ¬ІўЗТОЁТ»ЎЈЈЁ8ФЪaөДөЪ1О»Ј¬2ФЪaЦРЦШёҙБЛ2ҙОЈ© 2.assume_unique = TrueөДЗйҝцЈә a = np.array([3,2,1]) b = np.array([4,5,6]) c = np.setdiff1d(a, b,True) print(c)#[3 2 1] a = np.array([8,2,3,2,4,1]) b = np.array([7,4,5,6,3]) c = np.setdiff1d(a, b,True) print(c)#[8 2 2 1] a = np.array([8,2,3,4,2,4,1]) b = np.array([7,9,5,6,3]) c = np.setdiff1d(a, b,True) print(c)#[8 2 4 2 4 1] ҝЙТФҝҙіц°СФЪaЦРөДө«КЗІ»ФЪbЦРөДФӘЛШ°ҙaЦРөДЛіРтЕЕРтЈ¬ІўЗТІ»әПІўЦШёҙөДФӘЛШЈ¬јҙјЩ¶ЁКдИлКэЧйТІКЗОЁТ»өДЈ¬ТтҙЛПаұИУЪFalseИ·КөМбЙэБЛФЛЛгЛЩ¶ИЎЈ ИэЎўХыМеҙъВлimport numpy as np def main(): a = np.array([1,2,3]) b = np.array([4,5,6]) c = np.setdiff1d(a, b) print(c)#[1 2 3] a = np.array([1,2,3]) b = np.array([1,2,3]) c = np.setdiff1d(a, b) print(c)#[] a = np.array([1,2,3]) b = np.array([2,3,4]) c = np.setdiff1d(a, b) print(c)#[1] a = np.array([1,2,3,4]) b = np.array([3,4,5,6]) c = np.setdiff1d(a, b) print(c)#[1 2] a = np.array([1,2,3,2,4,1]) b = np.array([3,4,5,6]) c = np.setdiff1d(a, b) print(c)#[1 2] a = np.array([8,2,3,2,4,1]) b = np.array([7,4,5,6,3]) c = np.setdiff1d(a, b) print(c)#[1 2 8] a = np.array([3,2,1]) b = np.array([4,5,6]) c = np.setdiff1d(a, b,True) print(c)#[3 2 1] a = np.array([8,2,3,2,4,1]) b = np.array([7,4,5,6,3]) c = np.setdiff1d(a, b,True) print(c)#[8 2 2 1] a = np.array([8,2,3,4,2,4,1]) b = np.array([7,9,5,6,3]) c = np.setdiff1d(a, b,True) print(c)#[8 2 4 2 4 1] if __name__ == '__main__': main() 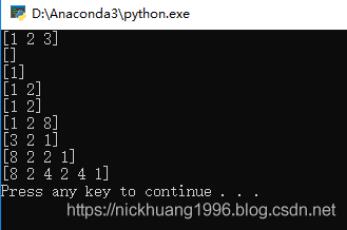
І№ідЈәPythonұаіМЦ®numpyҝвәҜКэin1dөДК№УГ ЧоҪьАыУГPythonЧчКэЦө·ЦОцКұК№УГөҪnumpyҝвПВөДin1dәҜКэЎЈin1dәҜКэУлexcelЦРvlookupәҜКэәНMATLABЦРismemberәҜКэУРПаЛЖЦ®ҙҰЎЈЖдЧчУГФЪУЪФЪРтБРBЦРС°ХТУлРтБРAПаН¬өДЦөЈ¬Іў·ө»ШТ»ВЯјӯЦөЈЁTrue,FalseЈ©»тВЯјӯЦө№№іЙөДПтБҝЎЈ ҫЯМеАэЧУјыПВОДЙиmaskОӘВЯјӯЦөПтБҝЈ¬ҫШХуxөДөЪТ»БРОӘҙэІйХТПтБҝЈ¬dОӘұ»ІйСҜПтБҝ(»тЦө)Ј¬јҙІйХТxЦРУлdЦРЦё¶ЁФӘЛШПаН¬өДЦөЈ¬Іў·ө»ШВЯјӯЦөПтБҝmaskЎЈmaskКЗУЙТ»ПөБРTrueәНFalseЦө№№іЙЈ¬TrueҙъұнХТөҪПаН¬өДЦөЈ¬¶шFalseҙъұнГ»ХТөҪПаН¬өДЦөЎЈСЭКҫИзПВЈә mask= np.in1d(x.values[:,1],d[1],invert=False) ##xОӘDataFrameРНКэҫЭЈ¬x.values[:,1]ұнКҫИЎөЪ¶юБРЦөx_temp=x[mask] КҫИЎөЪ¶юБРЦө ёГАэЦјФЪІйХТ x өДөЪ¶юБРЦөЦРУлdПтБҝЦРөЪ¶юёцФӘЛШПаН¬өДІҝ·Ц Ј¬Іў·ө»ШmaskВЯјӯПтБҝЈ»И»әуx_temp·ө»ШxЦРmaskВЯјӯЦөОӘTrueөДРРЎЈ maskПтБҝөДАаРНОӘboolЈ¬ІйҝҙҫЯМеЦөПВНјЛщКҫЈә 
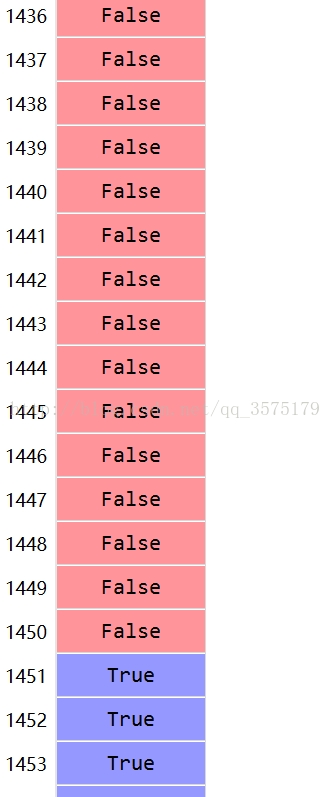
ЦөөГЧўТвөДөШ·ҪФЪУЪin1dәҜКэЦРinvertІОКэөДЙиЦГЎЈөұinvert=TrueКұЈ¬maskЦРөДФӘЛШЦөОӘTrueөДІҝ·Ц¶Фx.values[:,1]ЦРУлөұЗ°ІйХТөДФӘЛШd[i]І»Н¬өДІҝ·Ц(iОӘөұЗ°ІйХТО»ЦГ)Ј¬ПаН¬өДІҝ·ЦФтОӘfalseЈ»өұinvert=FalseКұЈ¬maskЦРөДФӘЛШЦөОӘTrueөДІҝ·Ц¶Фx.values[:,1]ЦРУлөұЗ°ІйХТөДФӘЛШd[i]ПаН¬өДІҝ·Ц(iОӘөұЗ°ІйХТО»ЦГ)ЎЈ СЭКҫјыПВНјЈә өұmask= np.in1d(x.values[:,1],d[2],invert=True) 
өұmask= np.in1d(x.values[:,1],d[2],invert=False)Кұ 
ТФЙПОӘёцИЛҫӯСйЈ¬ПЈНыДЬёшҙујТТ»ёцІОҝјЈ¬ТІПЈНыҙујТ¶а¶аЦ§іЦ51zixue.netЎЈИзУРҙнОу»тОҙҝјВЗНкИ«өДөШ·ҪЈ¬НыІ»БЯҙНҪМЎЈ
CУпСФКөПЦ¶юІжЛСЛчКчөДНкХыЧЬҪб
Python»щҙЎЦ®SocketНЁРЕФӯАн |




