这篇教程python爬虫系列网络请求案例详解写得很实用,希望能帮到您。
学习了之前的基础和爬虫基础之后,我们要开始学习网络请求了。 先来看看urllib
urllib的介绍urllib是Python自带的标准库中用于网络请求的库,无需安装,直接引用即可。
主要用来做爬虫开发,API数据获取和测试中使用。
urllib库的四大模块: - urllib.request: 用于打开和读取url
- urllib.error : 包含提出的例外,urllib.request
- urllib.parse:用于解析url
- urllib.robotparser:用于解析robots.txt
案例# 作者:互联网老辛# 开发时间:2021/4/5/0005 8:23import urllib.parsekw={'wd':"互联网老辛"}result=urllib.parse.urlencode(kw)print(result)#解码res=urllib.parse.unquote(result)print(res)
浏览器中会把互联网老辛,改成非中文的形式 我在浏览器中搜互联网老辛,然后把浏览中的复制下来: 
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E4%BA%92%E8%81%94%E7%BD%91%E8%80%81%E8%BE%9B&fenlei=256&oq=%25E7%25BE%258E%25E5%259B%25A2&rsv_pq=aa5b8079001eec3e&rsv_t=9ed1VMqcHzdaH7l2O1E8kMBcAS8OfSAGWHaXNgUYsfoVtGNbNVzHRatL1TU&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_btype=t&inputT=3542&rsv_sug2=0&rsv_sug4=3542 仔细看下,加粗的部分是不是就是我们在代码中输出的wd的结果
发送请求模拟浏览器发起一个http请求,并获取请求的响应结果 - urllib.request.urlopen 的语法格式:
urlopen(url,data=None,[timeout]*,cafile=None,capath=None,cadefault=False,context=None
参数说明:url: str类型的地址,也就是要访问的URL,例如https://www/baidu.com
data: 默认值为None
urlopen: 函数返回的是一个http.client.HTTPResponse对象
代码案例get请求 # 作者:互联网老辛# 开发时间:2021/4/5/0005 8:23import urllib.requesturl="http://www.geekyunwei.com/"resp=urllib.request.urlopen(url)html=resp.read().decode('utf-8') #将bytes转成utf-8类型print(html)为什么要改成utf-8而不是gbk, 这里要看网页的检查网页源代码里是什么: 
发送请求-Request请求我们去爬取豆瓣 # 作者:互联网老辛# 开发时间:2021/4/5/0005 8:23import urllib.requesturl="https://movie.douban.com/"resp=urllib.request.urlopen(url)print(resp) 豆瓣有反爬虫策略,会直接报418错误
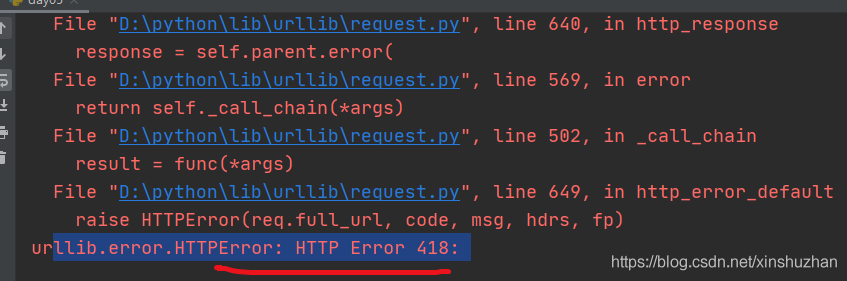
对于这种我们需要伪装请求头: 我们找到网页中的user-Agent: User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400 # 作者:互联网老辛# 开发时间:2021/4/5/0005 8:23import urllib.requesturl="https://movie.douban.com/"headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}#构建请求对象req=urllib.request.Request(url,headers=headers)#使用urlopen打开请求resp=urllib.request.urlopen(req)#从响应结果中读取数据html=resp.read().decode('utf-8')print(html)这样我们就用Python成功的伪装成浏览器获取到了数据
IP代理opener的使用,构建自己的opener发送请求 # 作者:互联网老辛# 开发时间:2021/4/5/0005 8:23import urllib.requesturl="https://www.baidu.com/"headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}#构建请求对象req=urllib.request.Request(url,headers=headers)opener=urllib.request.build_opener()resp=opener.open(req)print(resp.read().decode())如果你不停的发送请求,他有可能给你禁止IP, 所以我们每隔一段时间就换一个IP代理。
IP代理分类: - 透明代理: 目标网站知道你使用了代理并且知道你的源IP地址,这种代理肯定不符合我们的初衷
- 匿名代理: 网站知道你使用了代理,但不知道你的源ip
- 高匿代理: 这是最保险的方式,目录网站不知道你使用了代理
ip代理的方式: 免费的: https://www.xicidaili.com/nn/ 收费的: 大象代理,快代理,芝麻代理 # 作者:互联网老辛# 开发时间:2021/4/5/0005 8:23from urllib.request import build_openerfrom urllib.request import ProxyHandlerproxy=ProxyHandler({'https':'222.184.90.241:4278'})opener=build_opener(proxy)url='https://www.baidu.com/'resp=opener.open(url)print(resp.read().decode('utf-8'))百度其实能够做到反爬,即使是高匿代理也做不到百分百的绕过。
使用cookie为什么使用cookie? 使用cookie主要是为了解决http的无状态性。
使用步骤: - 实例化MozillaCookiejar(保存cookie)
- 创建handler对象(cookie的处理器)
- 创建opener对象
- 打开网页(发送请求获取响应)
- 保存cookie文件
案例: 获取百度贴的cookie存储下来 import urllib.requestfrom http import cookiejarfilename='cookie.txt'def get_cookie(): cookie=cookiejar.MozillaCookieJar(filename) #创建handler对象 handler=urllib.request.HTTPCookieProcessor(cookie) opener=urllib.request.build_opener((handler)) #请求网址 url='https://tieba.baidu.com/f?kw=python3&fr=index' resp=opener.open(url) # 保存cookie cookie.save()#读取数据def use_cookie(): #实例化MozillaCookieJar cookie=cookiejar.MozillaCookieJar() #加载cookie文件 cookie.load(filename) print(cookie)if __name__=='__main--': use_cookie() #get_cookie()
异常处理我们爬取一个访问不了的网站来捕获异常 # 作者:互联网老辛# 开发时间:2021/4/6/0006 7:38import urllib.requestimport urllib.errorurl='https://www.google.com'try: resp=urllib.request.urlopen(url)except urllib.error.URLError as e: print(e.reason) 可以看到捕获到了异常 
网络请求我们已经学完了,后面我们将学习几个常用的库,之后就可以进行数据的爬取了。 到此这篇关于python爬虫系列网络请求案例详解的文章就介绍到这了,更多相关python爬虫网络请求内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
39条Python语句实现数字华容道
制作Python数字华容道的实现(可选择关卡) |




