这篇教程PyTorch 迁移学习实践(几分钟即可训练好自己的模型)写得很实用,希望能帮到您。
前言如果你认为深度学习非常的吃GPU,或者说非常的耗时间,训练一个模型要非常久,但是你如果了解了迁移学习那你的模型可能只需要几分钟,而且准确率不比你自己训练的模型准确率低,本节我们将会介绍两种方法来实现迁移学习 迁移学习方法介绍 微调网络的方法实现迁移学习,更改最后一层全连接,并且微调训练网络将模型看成特征提取器,如果一个模型的预训练模型非常的好,那完全就把前面的层看成特征提取器,冻结所有层并且更改最后一层,只训练最后一层,这样我们只训练了最后一层,训练会非常的快速
迁移基本步骤 - 数据的准备
- 选择数据增广的方式
- 选择合适的模型
- 更换最后一层全连接
- 冻结层,开始训练
- 选择预测结果最好的模型保存
需要导入的包import zipfile # 解压文件import torchvisionfrom torchvision import datasets, transforms, modelsimport torchfrom torch.utils.data import DataLoader, Datasetimport osimport cv2import numpy as npimport matplotlib.pyplot as pltfrom PIL import Imageimport copy 数据准备本次实验的数据到这里下载
首先按照上一章节讲的数据读取方法来准备数据 # 解压数据到指定文件def unzip(filename, dst_dir): z = zipfile.ZipFile(filename) z.extractall(dst_dir)unzip('./data/hymenoptera_data.zip', './data/')# 实现自己的Dataset方法,主要实现两个方法__len__和__getitem__class MyDataset(Dataset): def __init__(self, dirname, transform=None): super(MyDataset, self).__init__() self.classes = os.listdir(dirname) self.images = [] self.transform = transform for i, classes in enumerate(self.classes): classes_path = os.path.join(dirname, classes) for image_name in os.listdir(classes_path): self.images.append((os.path.join(classes_path, image_name), i)) def __len__(self): return len(self.images) def __getitem__(self, idx): image_name, classes = self.images[idx] image = Image.open(image_name) if self.transform: image = self.transform(image) return image, classes def get_claesses(self): return self.classes# 分布实现训练和预测的transformtrain_transform = transforms.Compose([ transforms.Grayscale(3), transforms.RandomResizedCrop(224), #随机裁剪一个area然后再resize transforms.RandomHorizontalFlip(), #随机水平翻转 transforms.Resize(size=(256, 256)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])val_transform = transforms.Compose([ transforms.Grayscale(3), transforms.Resize(size=(256, 256)), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])# 分别实现loadertrain_dataset = MyDataset('./data/hymenoptera_data/train/', train_transform)train_loader = DataLoader(train_dataset, shuffle=True, batch_size=32)val_dataset = MyDataset('./data/hymenoptera_data/val/', val_transform)val_loader = DataLoader(val_dataset, shuffle=True, batch_size=32)选择预训练的模型这里我们选择了resnet18在ImageNet 1000类上进行了预训练的 model = models.resnet18(pretrained=True) # 使用预训练 使用model.buffers查看网络基本结构 <bound method Module.buffers of ResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer2): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer3): Sequential( (0): BasicBlock( (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer4): Sequential( (0): BasicBlock( (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=512, out_features=1000, bias=True))> 我们现在需要做的就是将最后一层进行替换 only_train_fc = Trueif only_train_fc: for param in model.parameters(): param.requires_grad_(False)fc_in_features = model.fc.in_featuresmodel.fc = torch.nn.Linear(fc_in_features, 2, bias=True) 注释:only_train_fc如果我们设置为True那么就只训练最后的fc层
现在观察一下可导的参数有那些(在只训练最后一层的情况下)
for i in model.parameters(): if i.requires_grad: print(i) Parameter containing:tensor([[ 0.0342, -0.0336, 0.0279, ..., -0.0428, 0.0421, 0.0366], [-0.0162, 0.0286, -0.0379, ..., -0.0203, -0.0016, -0.0440]], requires_grad=True)Parameter containing:tensor([-0.0120, -0.0086], requires_grad=True) 注释:由于最后一层使用了bias因此我们会多加两个参数
训练主体的实现epochs = 50loss_fn = torch.nn.CrossEntropyLoss()opt = torch.optim.SGD(lr=0.01, params=model.parameters())device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')# device = torch.device('cpu')model.to(device)opt_step = torch.optim.lr_scheduler.StepLR(opt, step_size=20, gamma=0.1)max_acc = 0epoch_acc = []epoch_loss = []for epoch in range(epochs): for type_id, loader in enumerate([train_loader, val_loader]): mean_loss = [] mean_acc = [] for images, labels in loader: if type_id == 0: # opt_step.step() model.train() else: model.eval() images = images.to(device) labels = labels.to(device).long() opt.zero_grad() with torch.set_grad_enabled(type_id==0): outputs = model(images) _, pre_labels = torch.max(outputs, 1) loss = loss_fn(outputs, labels) if type_id == 0: loss.backward() opt.step() acc = torch.sum(pre_labels==labels) / torch.tensor(labels.shape[0], dtype=torch.float32) mean_loss.append(loss.cpu().detach().numpy()) mean_acc.append(acc.cpu().detach().numpy()) if type_id == 1: epoch_acc.append(np.mean(mean_acc)) epoch_loss.append(np.mean(mean_loss)) if max_acc < np.mean(mean_acc): max_acc = np.mean(mean_acc) print(type_id, np.mean(mean_loss),np.mean(mean_acc))print(max_acc)在使用cpu训练的情况,也能快速得到较好的结果,这里训练了50次,其实很快的就已经得到了很好的结果了
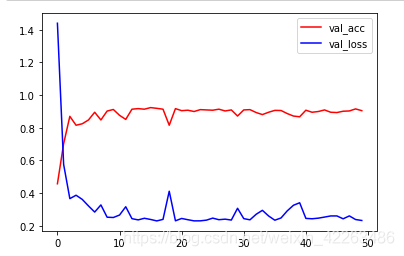
总结本节我们使用了预训练模型,发现大概10个epoch就可以很快的得到较好的结果了,即使在使用cpu情况下训练,这也是迁移学习为什么这么受欢迎的原因之一了,如果读者有兴趣可以自己试一试在不冻结层的情况下,使用方法一能否得到更好的结果 到此这篇关于PyTorch 迁移学习实践(几分钟即可训练好自己的模型)的文章就介绍到这了,更多相关PyTorch 迁移内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
解决python3 中的np.load编码问题
Python 字符串去除空格的五种方法 |

