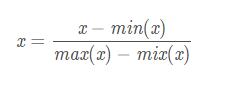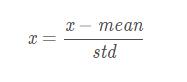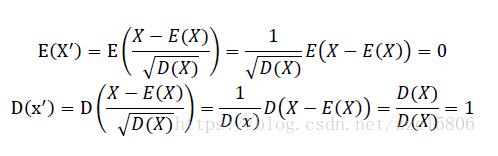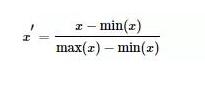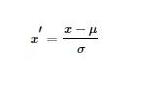етЦЊНЬГЬPython3 ГЃгУЪ§ОнБъзМЛЏЗНЗЈЯъНтаДЕУКмЪЕгУЃЌЯЃЭћФмАяЕНФњЁЃ
Ъ§ОнБъзМЛЏЪЧЛњЦїбЇЯАЁЂЪ§ОнЭкОђжаГЃгУЕФвЛжжЗНЗЈЁЃАќРЈЮвздМКдкзіЩюЖШбЇЯАЗНУцЕФбаОПЪБЃЌЪ§ОнБъзМЛЏЪЧзюЛљБОЕФвЛИіВНжшЁЃ Ъ§ОнБъзМЛЏжївЊЪЧгІЖдЬиеїЯђСПжаЪ§ОнКмЗжЩЂЕФЧщПіЃЌЗРжЙаЁЪ§ОнБЛДѓЪ§ОнЃЈОјЖджЕЃЉЭЬВЂЕФЧщПіЁЃ СэЭтЃЌЪ§ОнБъзМЛЏвВгаМгЫйбЕСЗЃЌЗРжЙЬнЖШБЌеЈЕФзїгУЁЃ ЯТУцЪЧДгРюКъвуНЬЪкЪгЦЕжаНиЯТРДЕФСНеХЭМЁЃ 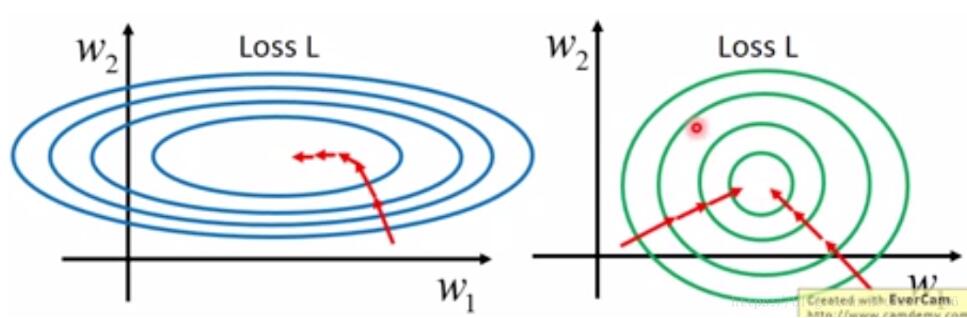
зѓЭМБэЪОЮДОЙ§Ъ§ОнБъзМЛЏДІРэЕФlossИќаТКЏЪ§ЃЌгвЭМБэЪООЙ§Ъ§ОнБъзМЛЏКѓЕФlossИќаТЭМЁЃПЩМћОЙ§БъзМЛЏКѓЕФЪ§ОнИќШнвзЕќДњЕНзюгХЕуЃЌЖјЧвЪеСВИќПьЁЃ вЛЁЂ[0, 1] БъзМЛЏ[0, 1] БъзМЛЏЪЧзюЛљБОЕФвЛжжЪ§ОнБъзМЛЏЗНЗЈЃЌжИЕФЪЧНЋЪ§ОнбЙЫѕЕН0ЁЋ1жЎМфЁЃ БъзМЛЏЙЋЪНШчЯТ 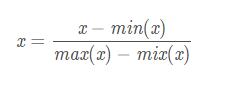
ДњТыЪЕЯж def MaxMinNormalization(x, min, max): """[0,1] normaliaztion""" x = (x - min) / (max - min) return x Лђеп def MaxMinNormalization(x): """[0,1] normaliaztion""" x = (x - np.min(x)) / (np.max(x) - np.min(x)) return x ЖўЁЂZ-scoreБъзМЛЏZ-scoreБъзМЛЏЪЧЛљгкЪ§ОнОљжЕКЭЗНВюЕФБъзМЛЏЛЏЗНЗЈЁЃБъзМЛЏКѓЕФЪ§ОнЪЧОљжЕЮЊ0ЃЌЗНВюЮЊ1ЕФе§ЬЌЗжВМЁЃетжжЗНЗЈвЊЧѓдЪМЪ§ОнЕФЗжВМПЩвдНќЫЦЮЊИпЫЙЗжВМЃЌЗёдђаЇЙћЛсКмВюЁЃ БъзМЛЏЙЋЪНШчЯТ 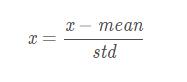
ЯТУцЃЌЮвУЧПДПДЮЊЪВУДОЙ§етжжБъзМЛЏЗНЗЈДІРэКѓЕФЪ§ОнЮЊЪЧОљжЕЮЊ0ЃЌЗНВюЮЊ1 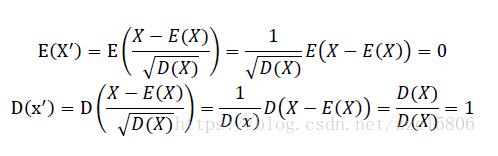
ДњТыЪЕЯж def ZscoreNormalization(x, mean_, std_): """Z-score normaliaztion""" x = (x - mean_) / std_ return x Лђеп def ZscoreNormalization(x): """Z-score normaliaztion""" x = (x - np.mean(x)) / np.std(x) return x ВЙГфЃКPythonЪ§ОндЄДІРэЃКГЙЕзРэНтБъзМЛЏКЭЙщвЛЛЏ Ъ§ОндЄДІРэЪ§ОнжаВЛЭЌЬиеїЕФСПИйПЩФмВЛвЛжТЃЌЪ§жЕМфЕФВюБ№ПЩФмКмДѓЃЌВЛНјааДІРэПЩФмЛсгАЯьЕНЪ§ОнЗжЮіЕФНсЙћЃЌвђДЫЃЌашвЊЖдЪ§ОнАДеевЛЖЈБШР§НјааЫѕЗХЃЌЪЙжЎТфдквЛИіЬиЖЈЕФЧјгђЃЌБугкНјаазлКЯЗжЮіЁЃ ГЃгУЕФЗНЗЈгаСНжжЃКзюДѓ - зюаЁЙцЗЖЛЏЃКЖддЪМЪ§ОнНјааЯпадБфЛЛЃЌНЋЪ§ОнгГЩфЕН[0,1]ЧјМф 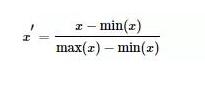
Z-ScoreБъзМЛЏЃКНЋдЪМЪ§ОнгГЩфЕНОљжЕЮЊ0ЁЂБъзМВюЮЊ1ЕФЗжВМЩЯ 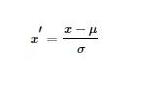
ЮЊЪВУДвЊБъзМЛЏ/ЙщвЛЛЏЃПЬсЩ§ФЃаЭОЋЖШЃКБъзМЛЏ/ЙщвЛЛЏКѓЃЌВЛЭЌЮЌЖШжЎМфЕФЬиеїдкЪ§жЕЩЯгавЛЖЈБШНЯадЃЌПЩвдДѓДѓЬсИпЗжРрЦїЕФзМШЗадЁЃ МгЫйФЃаЭЪеСВЃКБъзМЛЏ/ЙщвЛЛЏКѓЃЌзюгХНтЕФбАгХЙ§ГЬУїЯдЛсБфЕУЦНЛКЃЌИќШнвзе§ШЗЕФЪеСВЕНзюгХНтЁЃ ШчЯТЭМЫљЪОЃК 
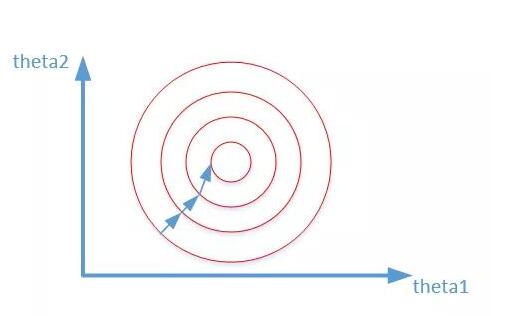
ФФаЉЛњЦїбЇЯАЫуЗЈашвЊБъзМЛЏКЭЙщвЛЛЏ1ЃЉашвЊЪЙгУЬнЖШЯТНЕКЭМЦЫуОрРыЕФФЃаЭвЊзіЙщвЛЛЏЃЌвђЮЊВЛзіЙщвЛЛЏЛсЪЙЪеСВЕФТЗОЖГЬzзжаЭЯТНЕЃЌЕМжТЪеСВТЗОЖЬЋТ§ЃЌЖјЧвВЛШнвзевЕНзюгХНтЃЌЙщвЛЛЏжЎКѓМгПьСЫЬнЖШЯТНЕЧѓзюгХНтЕФЫйЖШЃЌВЂгаПЩФмЬсИпОЋЖШЁЃБШШчЫЕЯпадЛиЙщЁЂТпМЛиЙщЁЂadaboostЁЂxgboostЁЂGBDTЁЂSVMЁЂNeuralNetworkЕШЁЃашвЊМЦЫуОрРыЕФФЃаЭашвЊзіЙщвЛЛЏЃЌБШШчЫЕKNNЁЂKMeansЕШЁЃ 2ЃЉИХТЪФЃаЭЁЂЪїаЮНсЙЙФЃаЭВЛашвЊЙщвЛЛЏЃЌвђЮЊЫќУЧВЛЙиаФБфСПЕФжЕЃЌЖјЪЧЙиаФБфСПЕФЗжВМКЭБфСПжЎМфЕФЬѕМўИХТЪЃЌШчОіВпЪїЁЂЫцЛњЩСжЁЃ 
ГЙЕзРэНтБъзМЛЏКЭЙщвЛЛЏ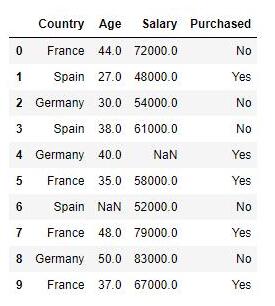
ЪОР§Ъ§ОнМЏАќКЌвЛИіздБфСПЃЈвбЙКТђЃЉКЭШ§ИівђБфСПЃЈЙњМвЃЌФъСфКЭаНЫЎЃЉЃЌПЩвдПДГігУаНЫЎЗЖЮЇБШФъСфПэЕФЖрЃЌШчЙћжБНгНЋЪ§ОнгУгкЛњЦїбЇЯАФЃаЭЃЈБШШчKNNЁЂKMeansЃЉЃЌФЃаЭНЋЭъШЋгааНЫЎжїЕМЁЃ #ЕМШыЪ§Онimport numpy as npimport matplotlib.pyplot as pltimport pandas as pddf = pd.read_csv('Data.csv')ШБЪЇжЕОљжЕЬюГф,ДІРэзжЗћаЭБфСПdf['Salary'].fillna((df['Salary'].mean()), inplace= True)df['Age'].fillna((df['Age'].mean()), inplace= True)df['Purchased'] = df['Purchased'].apply(lambda x: 0 if x=='No' else 1)df=pd.get_dummies(data=df, columns=['Country']) 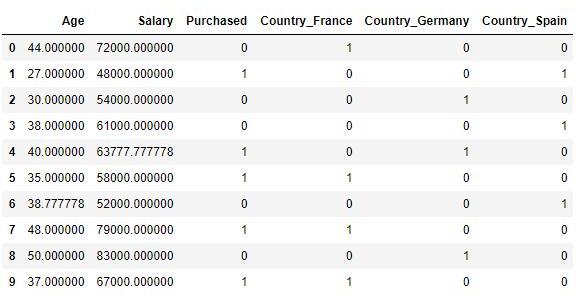
зюДѓ - зюаЁЙцЗЖЛЏfrom sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()scaler.fit(df)scaled_features = scaler.transform(df)df_MinMax = pd.DataFrame(data=scaled_features, columns=["Age", "Salary","Purchased","Country_France","Country_Germany", "Country_spain"]) 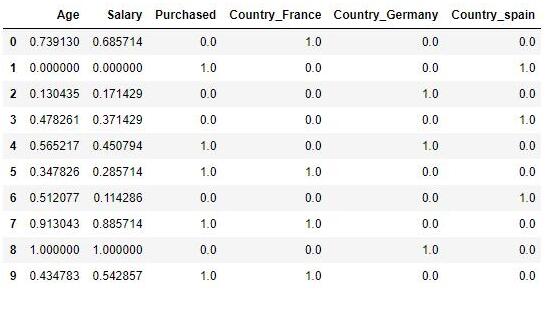
Z-ScoreБъзМЛЏfrom sklearn.preprocessing import StandardScalersc_X = StandardScaler()sc_X = sc_X.fit_transform(df)sc_X = pd.DataFrame(data=sc_X, columns=["Age", "Salary","Purchased","Country_France","Country_Germany", "Country_spain"]) 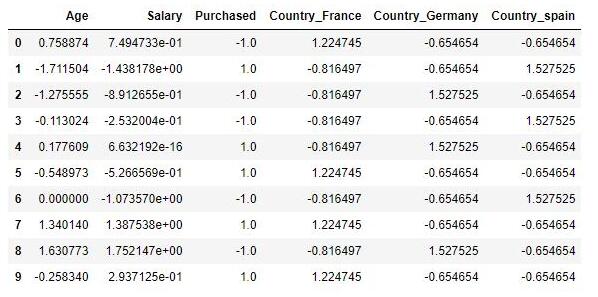
import seaborn as snsimport matplotlib.pyplot as pltimport statisticsplt.rcParams['font.sans-serif'] = ['Microsoft YaHei']fig,axes=plt.subplots(2,3,figsize=(18,12)) sns.distplot(df['Age'], ax=axes[0, 0])sns.distplot(df_MinMax['Age'], ax=axes[0, 1])axes[0, 1].set_title('ЙщвЛЛЏЗНВюЃК% s '% (statistics.stdev(df_MinMax['Age'])))sns.distplot(sc_X['Age'], ax=axes[0, 2])axes[0, 2].set_title('БъзМЛЏЗНВюЃК% s '% (statistics.stdev(sc_X['Age'])))sns.distplot(df['Salary'], ax=axes[1, 0])sns.distplot(df_MinMax['Salary'], ax=axes[1, 1])axes[1, 1].set_title('MinMaxЃКSalary')axes[1, 1].set_title('ЙщвЛЛЏЗНВюЃК% s '% (statistics.stdev(df_MinMax['Salary'])))sns.distplot(sc_X['Salary'], ax=axes[1, 2])axes[1, 2].set_title('StandardScaler:Salary')axes[1, 2].set_title('БъзМЛЏЗНВюЃК% s '% (statistics.stdev(sc_X['Salary'])))ПЩвдПДГіЙщвЛЛЏБШБъзМЛЏЗНЗЈВњЩњЕФБъзМВюаЁЃЌЪЙгУЙщвЛЛЏРДЫѕЗХЪ§ОнЃЌдђЪ§ОнНЋИќМЏжадкОљжЕИННќЁЃетЪЧгЩгкЙщвЛЛЏЕФЫѕЗХЪЧЁАХФБтЁБЭГвЛЕНЧјМфЃЈНігЩМЋжЕОіЖЈЃЉЃЌЖјБъзМЛЏЕФЫѕЗХЪЧИќМгЁАЕЏадЁБКЭЁАЖЏЬЌЁБЕФЃЌКЭећЬхбљБОЕФЗжВМгаКмДѓЕФЙиЯЕЁЃ ЫљвдЙщвЛЛЏВЛФмКмКУЕиДІРэРыШКжЕЃЌЖјБъзМЛЏЖдвьГЃжЕЕФТГАєадЧПЃЌдкаэЖрЧщПіЯТЃЌЫќгХгкЙщвЛЛЏЁЃ вдЩЯЮЊИіШЫОбщЃЌЯЃЭћФмИјДѓМввЛИіВЮПМЃЌвВЯЃЭћДѓМвЖрЖржЇГж51zixue.netЁЃШчгаДэЮѓЛђЮДПМТЧЭъШЋЕФЕиЗНЃЌЭћВЛСпДЭНЬЁЃ
jupyter notebookжаЭМЦЌЯдЪОВЛГіРДЕФНтОі
НтОіjupyter (python3) ЖСШЁЮФМўгіЕНЕФЮЪЬт |