这篇教程pandas的Series类型与基本操作详解写得很实用,希望能帮到您。
1 Series线性的数据结构, series是一个一维数组 Pandas 会默然用0到n-1来作为series的index, 但也可以自己指定index( 可以把index理解为dict里面的key )
1.1创造一个serise数据import pandas as pdimport numpy as nps = pd.Series([9, 'zheng', 'beijing', 128])print(s) 打印 0 9
1 zheng
2 beijing
3 128
dtype: object
访问其中某个数据 print(s[1:2])# 打印1 zhengdtype: object Series类型的基本操作: Series类型包括index和values两部分
In [14]: a = pd.Series({'a':1,'b':5})In [15]: a.indexOut[15]: Index(['a', 'b'], dtype='object')In [16]: a.values #返回一个多维数组numpy对象Out[16]: array([1, 5], dtype=int64)Series类型的操作类似ndarray类型
#自动索引和自定义索引并存,但不能混用In [17]: a[0] #自动索引Out[17]: 1#自定义索引In [18]: a['a']Out[18]: 1#不能混用In [20]: a[['a',1]]Out[20]:a 1.01 NaNdtype: float64 Series类型的操作类似Python字典类型
#通过自定义索引访问#对索引保留字in操作,值不可以In [21]: 'a' in aOut[21]: TrueIn [22]: 1 in aOut[22]: False Series类型在运算中会自动对齐不同索引的数据 In [29]: a = pd.Series([1,3,5],index = ['a','b','c'])In [30]: b = pd.Series([2,4,5,6],index = ['c,','d','e','b'])In [31]: a+bOut[31]:a NaNb 9.0c NaNc, NaNd NaNe NaNdtype: float64 Series对象可以随时修改并即刻生效 In [32]: a.index = ['c','d','e']In [33]: aOut[33]:c 1d 3e 5dtype: int64In [34]: a+bOut[34]:b NaNc NaNc, NaNd 7.0e 10.0dtype: float64
1.2 指定indeximport pandas as pdimport numpy as nps = pd.Series([9, 'zheng', 'beijing', 128, 'usa', 990], index=[1,2,3,'e','f','g'])print(s) 打印 1 9
2 zheng
3 beijing
e 128
f usa
g 990
dtype: object
根据索引找出值
1.3 用dictionary构造一个seriesimport pandas as pdimport numpy as nps = {"ton": 20, "mary": 18, "jack": 19, "car": None}sa = pd.Series(s, name="age")print(sa)打印 car NaN
jack 19.0
mary 18.0
ton 20.0
Name: age, dtype: float64
检测类型 print(type(sa)) # <class 'pandas.core.series.Series'>
1.4 用numpy ndarray构造一个Series生成一个随机数 import pandas as pdimport numpy as npnum_abc = pd.Series(np.random.randn(5), index=list('abcde'))num = pd.Series(np.random.randn(5))print(num)print(num_abc)# 打印0 -0.1028601 -1.1382422 1.4080633 -0.8935594 1.378845dtype: float64a -0.658398b 1.568236c 0.535451d 0.103117e -1.556231dtype: float64
1.5 选择数据import pandas as pdimport numpy as nps = pd.Series([9, 'zheng', 'beijing', 128, 'usa', 990], index=[1,2,3,'e','f','g'])print(s[1:3]) # 选择第1到3个, 包左不包右 zheng beijingprint(s[[1,3]]) # 选择第1个和第3个, zheng 128print(s[:-1]) # 选择第1个到倒数第1个, 9 zheng beijing 128 usa
1.6 操作数据import pandas as pdimport numpy as nps = pd.Series([9, 'zheng', 'beijing', 128, 'usa', 990], index=[1,2,3,'e','f','g'])sum = s[1:3] + s[1:3]sum1 = s[1:4] + s[1:4]sum2 = s[1:3] + s[1:4]sum3 = s[:3] + s[1:]print(sum)print(sum1)print(sum2)print(sum3) 打印 2 zhengzheng
3 beijingbeijing
dtype: object
2 zhengzheng
3 beijingbeijing
e 256
dtype: object
2 zhengzheng
3 beijingbeijing
e NaN
dtype: object
1 NaN
2 zhengzheng
3 beijingbeijing
e NaN
f NaN
g NaN
dtype: object
1.7 查找是否存在 范围查找 import pandas as pdimport numpy as np s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None} sa = pd.Series(s, name="age") print(sa[sa>19])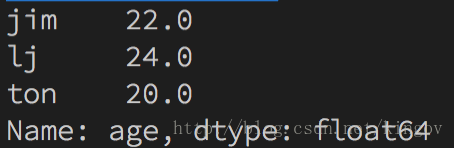
中位数 import pandas as pdimport numpy as np s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None} sa = pd.Series(s, name="age") print(sa.median()) # 20判断是否大于中位数 import pandas as pdimport numpy as np s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None} sa = pd.Series(s, name="age") print(sa>sa.median())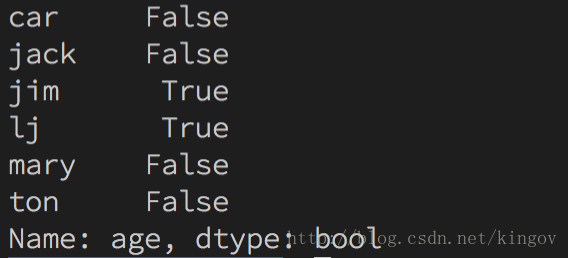
找出大于中位数的数 import pandas as pdimport numpy as np s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None} sa = pd.Series(s, name="age") print(sa[sa > sa.median()])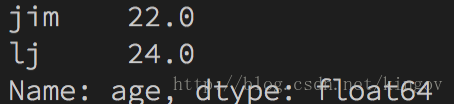
中位数 import pandas as pdimport numpy as np s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None} sa = pd.Series(s, name="age") more_than_midian = sa>sa.median() print(more_than_midian) print('---------------------') print(sa[more_than_midian])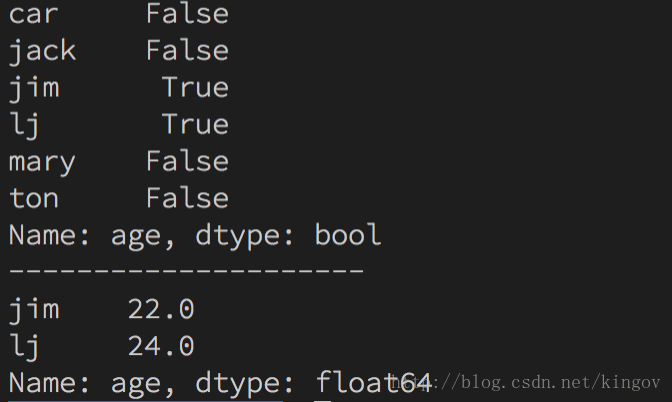
1.8 Series赋值import pandas as pdimport numpy as np s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None} sa = pd.Series(s, name="age") print(s) print('----------------') sa['ton'] = 99 print(sa)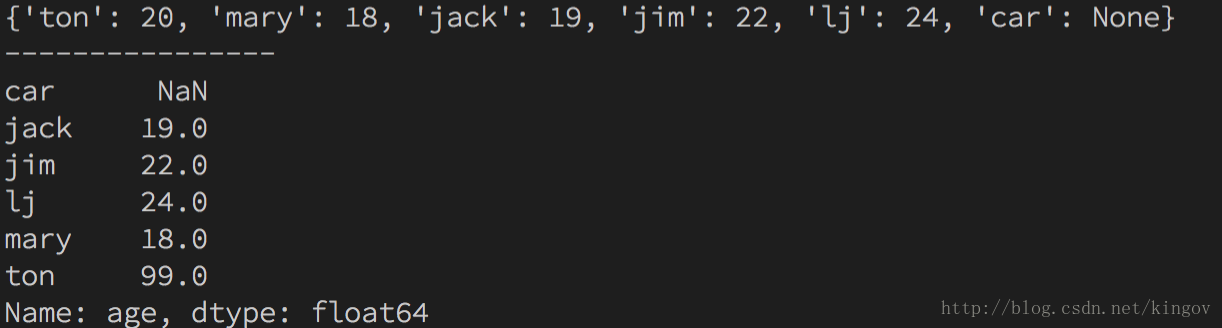
1.9 满足条件的统一赋值import pandas as pdimport numpy as np s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None} sa = pd.Series(s, name="age") print(s) # 打印原字典 print('---------------------') # 分割线 sa[sa>19] = 88 # 将所有大于19的同一改为88 print(sa) # 打印更改之后的数据 print('---------------------') # 分割线 print(sa / 2) # 将所有数据除以2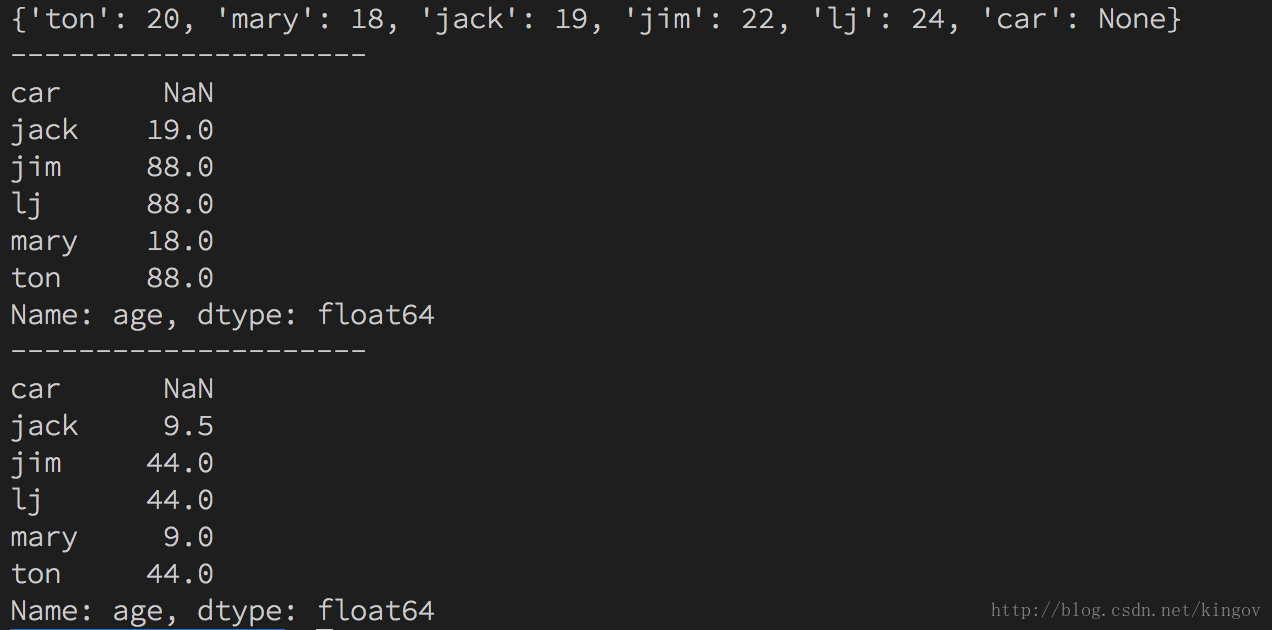
到此这篇关于pandas的Series类型与基本操作详解的文章就介绍到这了,更多相关pandas Series基本操作内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
python web框架的总结
python 绘制斜率图进行对比分析 |





