这篇教程初识Pytorch使用transforms的代码写得很实用,希望能帮到您。
首先,这次讲解的tansforms功能,通俗地讲,类似于在计算机视觉流程里的图像预处理部分的数据增强。 transforms的原理:
说明:图片(输入)通过工具得到结果(输出),这个工具,就是transforms模板工具,(tool=transforms.ToTensor()具体工具),使用工具result=tool(图片)
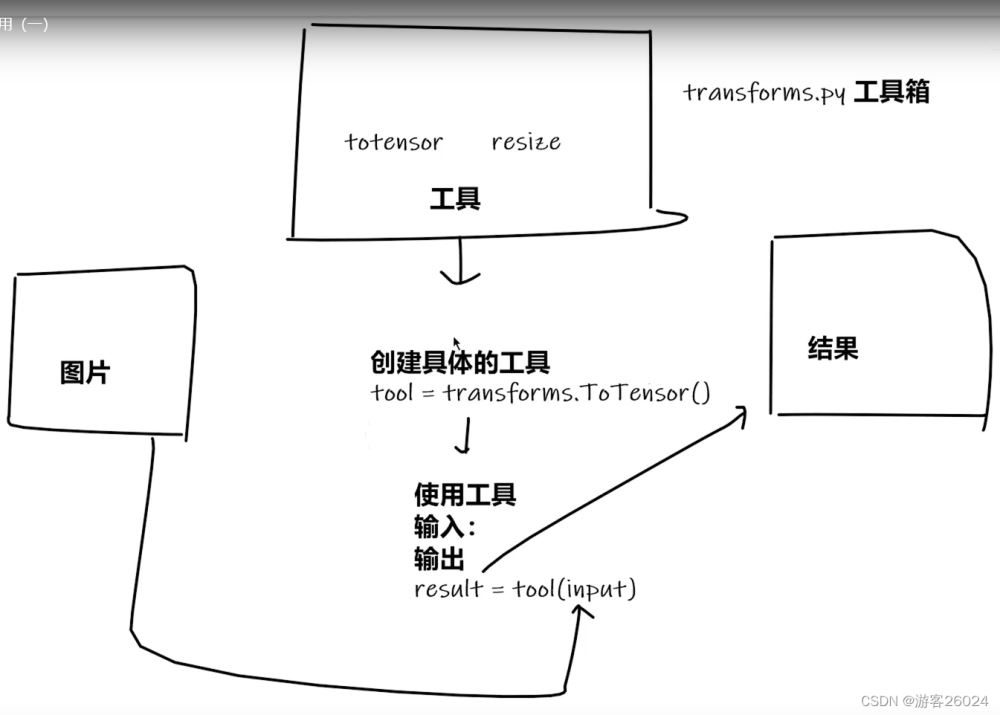
tansforms的调用与使用,由下图可得: 先创建一个transforms.Tensor(),使用from torchvision import transforms调包transforms去调init函数init去调用真正的transforms类,里面就有很多的方法(绿色五角星标注),例如:resize,ToTensor,CenterCrop(从这些方法可以看出,许多都是数据增强的方法)。 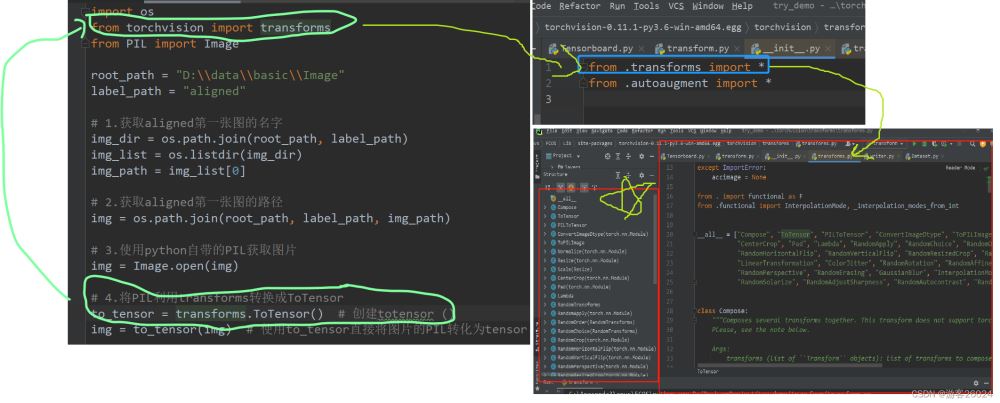
3. 接下来,上代码: import osfrom torchvision import transformsfrom PIL import Imageroot_path = "D://data//basic//Image"label_path = "aligned"# 1.获取aligned第一张图的名字img_dir = os.path.join(root_path, label_path)img_list = os.listdir(img_dir)img_path = img_list[0]# 2.获取aligned第一张图的路径img = os.path.join(root_path, label_path, img_path)# 3.使用python自带的PIL获取图片img = Image.open(img)# 4.将PIL利用transforms转换成ToTensorto_tensor = transforms.ToTensor() # 创建totensor ()img = to_tensor(img) # 使用to_tensor直接将图片的PIL转化为tensorprint(img)# transforms 代码结果: 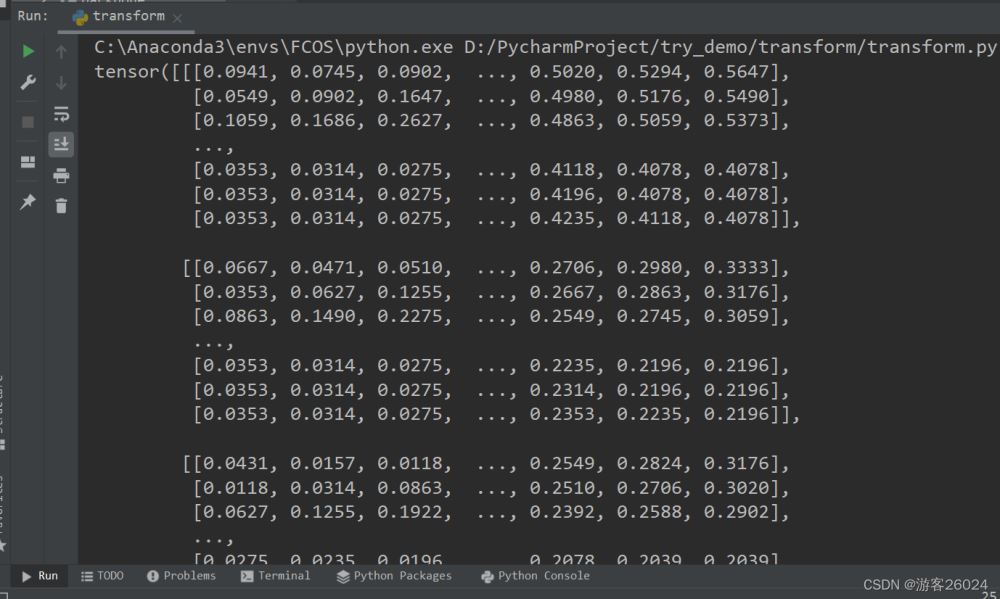
到此这篇关于初识Pytorch使用transforms的文章就介绍到这了,更多相关Pytorch使用transforms内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
基于Python实现PDF区域文本提取工具
OpenCV图像分割之分水岭算法与图像金字塔算法详解 |


