这篇教程一个入门级python爬虫教程详解写得很实用,希望能帮到您。
前言本文目的:根据本人的习惯与理解,用最简洁的表述,介绍爬虫的定义、组成部分、爬取流程,并讲解示例代码。
基础爬虫的定义:定向抓取互联网内容(大部分为网页)、并进行自动化数据处理的程序。主要用于对松散的海量信息进行收集和结构化处理,为数据分析和挖掘提供原材料。 今日t条就是一只巨大的“爬虫”。 爬虫由URL库、采集器、解析器组成。
流程如果待爬取的url库不为空,采集器会自动爬取相关内容,并将结果给到解析器,解析器提取目标内容后进行写入文件或入库等操作。 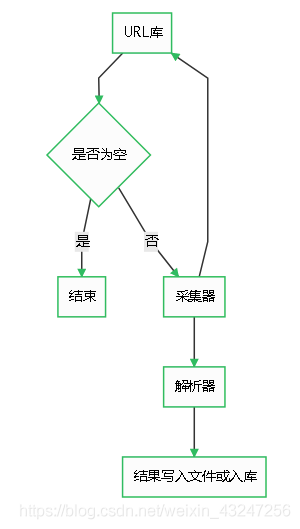
代码第一步:写一个采集器 如下是一个比较简单的采集器函数。需要用到requests库。
首先,构造一个http的header,里面有浏览器和操作系统等信息。如果没有这个伪造的header,可能会被目标网站的WAF等防护设备识别为机器代码并干掉。 然后,用requests库的get方法获取url内容。如果http响应代码是200 ok,说明页面访问正常,将该函数返回值设置为文本形式的html代码内容。 如果响应代码不是200 ok,说明页面不能正常访问,将函数返回值设置为特殊字符串或代码。 import requestsdef get_page(url): headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'} response = requests.get(url, headers= headers) if response.status_code == 200: return response.text else: return 'GET HTML ERROR !'第二步:解析器 解析器的作用是对采集器返回的html代码进行过滤筛选,提取需要的内容。
作为一个14年忠实用户,当然要用豆瓣举个栗子 _ 我们计划爬取豆瓣排名TOP250电影的8个参数:排名、电影url链接、电影名称、导演、上映年份、国家、影片类型、评分。整理成字典并写入文本文件。 待爬取的页面如下,每个页面包括25部电影,共计10个页面。 
在这里,必须要表扬豆瓣的前端工程师们,html标签排版非常工整具有层次,非常便于信息提取。 下面是“肖申克的救赎”所对应的html代码:(需要提取的8个参数用红线标注) 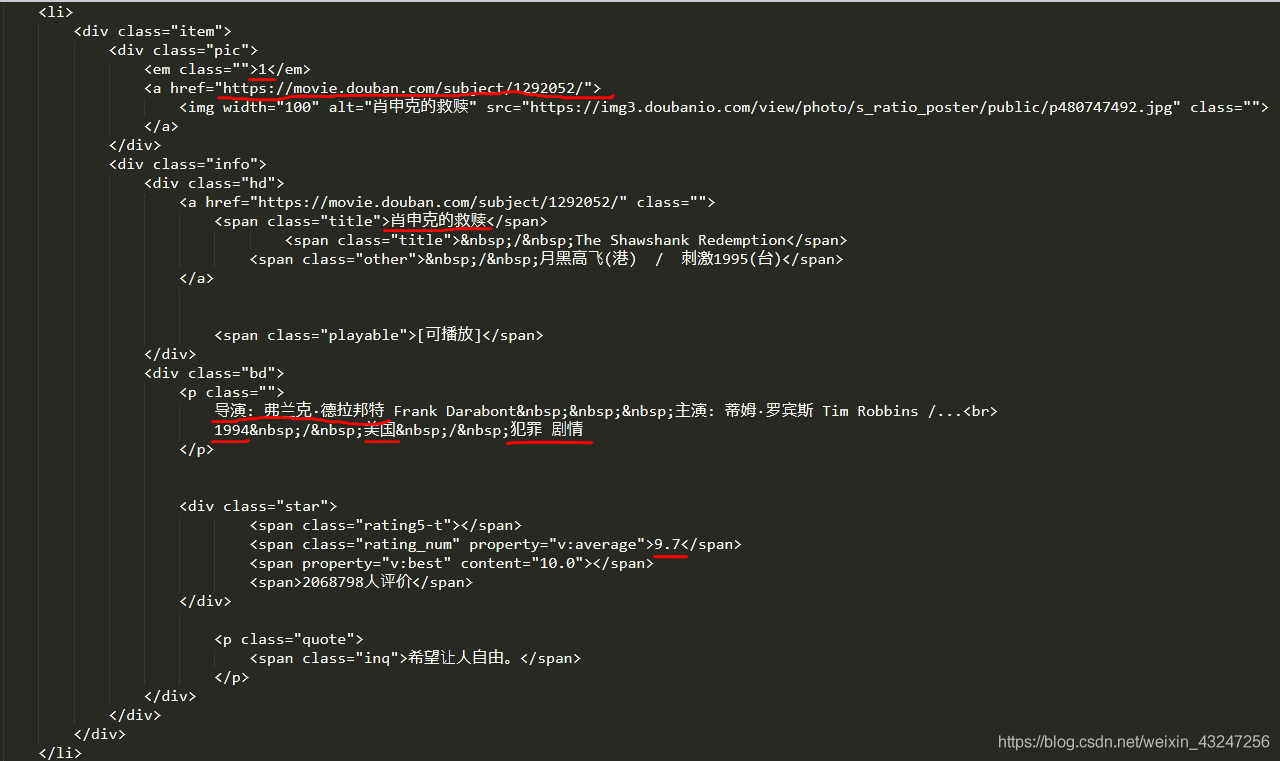
根据上面的html编写解析器函数,提取8个字段。该函数返回值是一个可迭代的序列。
我个人喜欢用re(正则表达式)提取内容。8个(.*?)分别对应需要提取的字段。 import redef parse_page(html): pattern = re.compile('<em class="">(.*?)</em>.*?<a href="(.*?)" rel="external nofollow" rel="external nofollow" >.*?<span class="title">(.*?)</span>.*?<div class="bd">.*?<p class="">(.*?) .*?<br>(.*?) / (.*?) / (.*?)</p>.*?<span class="rating_num".*?"v:average">(.*?)</span>' , re.S) items = re.findall(pattern , html) for item in items: yield { 'rank': item[0], 'href': item[1], 'name': item[2], 'director': item[3].strip()[4:], 'year': item[4].strip(), 'country': item[5].strip(), 'style': item[6].strip(), 'score': item[7].strip() }提取后的内容如下: 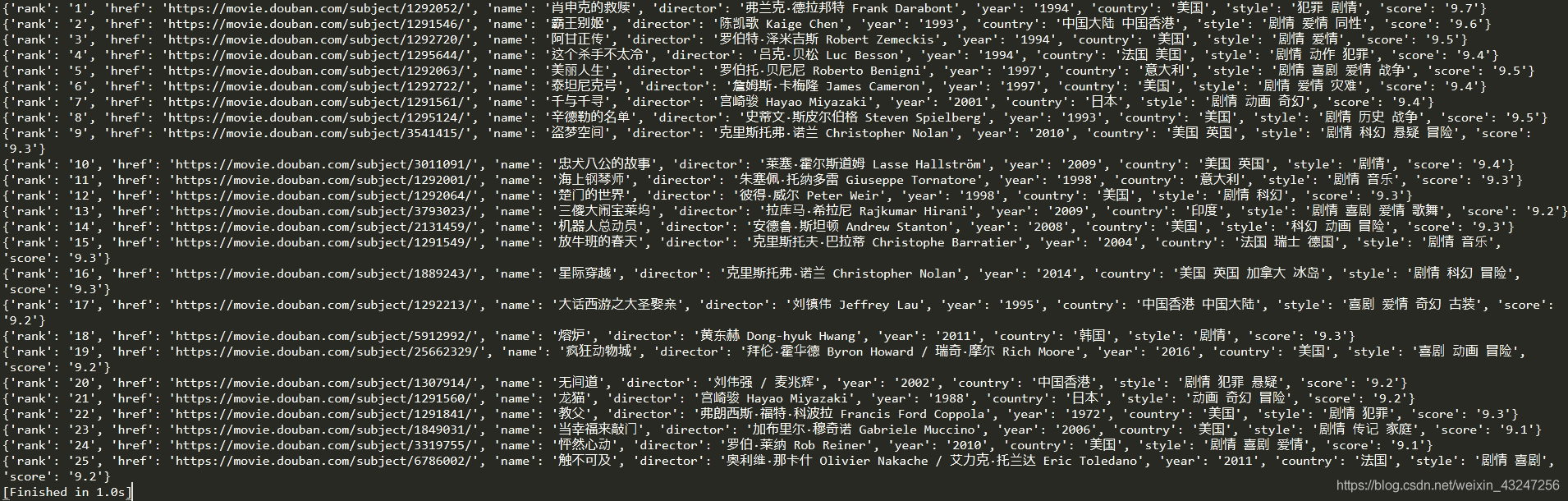
整理成完整的代码:(暂不考虑容错) import requestsimport reimport jsondef get_page(url): #采集器函数 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'} response = requests.get(url, headers= headers) if response.status_code == 200: return response.text else: return 'GET HTML ERROR ! 'def parse_page(html): #解析器函数 pattern = re.compile('<em class="">(.*?)</em>.*?<a href="(.*?)" rel="external nofollow" rel="external nofollow" >.*?<span class="title">(.*?)</span>.*?<div class="bd">.*?<p class="">(.*?) .*?<br>(.*?) / (.*?) / (.*?)</p>.*?<span class="rating_num".*?"v:average">(.*?)</span>' , re.S) items = re.findall(pattern , html) for item in items: yield { 'rank': item[0], 'href': item[1], 'name': item[2], 'director': item[3].strip()[4:], 'year': item[4].strip(), 'country': item[5].strip(), 'style': item[6].strip(), 'score': item[7].strip() }def write_to_file(content): #写入文件函数 with open('result.txt' , 'a' , encoding = 'utf-8') as file: file.write(json.dumps(content , ensure_ascii = False) + '/n')if __name__== "__main__": # 主程序 for i in range(10): url= 'https://movie.douban.com/top250?start='+ str(i*25)+ '&filter' for res in parse_page(get_page(url)): write_to_file(res)非常简洁,非常符合python简单、高效的特点。 说明: 需要掌握待爬取url的规律,才能利用for循环等操作自动化处理。
前25部影片的url是https://movie.douban.com/top250?start=0&filter,第26-50部影片url是https://movie.douban.com/top250?start=25&filter。规律就在start参数,将start依次设置为0、25、50、75。。。225,就能获取所有页面的链接。parse_page函数的返回值是一个可迭代序列,可以理解为字典的集合。运行完成后,会在程序同目录生成result.txt文件。内容如下: 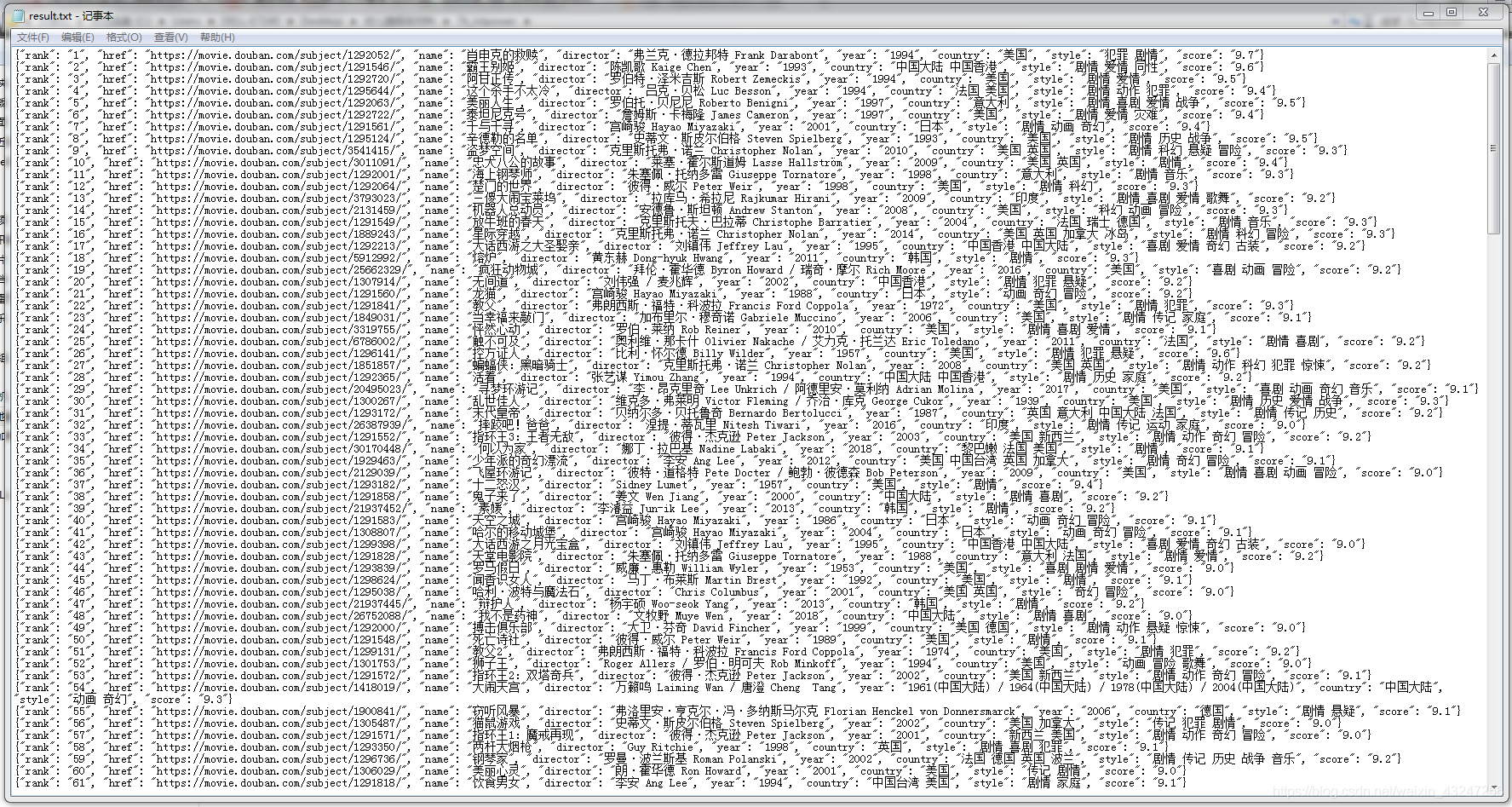
到此这篇关于一个入门级python爬虫教程详解的文章就介绍到这了,更多相关python爬虫入门教程内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
python+selenium爬取微博热搜存入Mysql的实现方法
Python3 + Appium + 安卓模拟器实现APP自动化测试并生成测试报告 |




